

|
保密级别: |
E |
|
撰写人: |
陈旺 |
|
编制日期: |
2026.06.08 |
|
最后修改日期: |
2026.06.08 |
|
一、硬件配置环境
|
硬件配置环境 |
|||
|
物料名称 |
编号 |
型号 |
单台数量 |
|
准系统 |
82811 |
劲群 4U8卡(SYS8480DG Gen4)TWG420X4 /12SATA/2000W*4) |
1 |
|
CPU |
1020189 |
Intel Xeon Gold 6530 |
2 |
|
内存 |
30376 |
三星 64G DDR5 4800 REG 内存 |
8 |
|
硬盘 |
2982 |
Intel SSD S4510 960G 2.5 SATA |
2 |
|
硬盘 |
2938 |
Kioxia(铠侠CD8-R)3.84T U.2 NVMe企业级SSD( KCD81RUG3T84) |
3 |
|
GPU |
NVIDIA A100 80G显存 定制版 |
2 |
|
|
GPU线材 |
190235 |
Tesla A100/A6000/A40显卡8pin供电线(TW G420X4机器使用) |
2 |
|
背板线材 |
190171 |
slimsas 8654 8i转 MCIO 1米 |
2 |
|
网卡 |
1401 |
东大网卡 FM-NHI350AM2-T2 |
1 |
|
电源线 |
1859 |
名线 1.8米电源线 |
2 |
|
RAID |
1259 |
阵列卡 LSI 9440 8i |
1 |
|
RAID线 |
190114 |
8643-8654(RSL38-1067)一对一 1米 |
1 |
二、软件配置环境
|
软件配置环境 |
|
|
配置项 |
详细信息 |
|
操作系统 |
Ubuntu 22.04.4 LTS (Kernel: 5.15.0-181) |
|
GPU 驱动 |
NVIDIA Driver 595.71.05 |
|
CUDA 工具链 |
CUDA Toolkit 13.2 (nvcc V13.2.51) |
|
DCGM 诊断工具 |
v4.5.3 (Build 17876) |
|
编译器 |
GCC 11.4.0 / CMake 3.31.12 |
|
集合通信库 |
NCCL |
|
算力性能测试工具 |
CUTLASS 4.0.0 |
|
带宽性能测试工具 |
nvbandwidth v0.9 (源自 NVIDIA 官方库) |
|
压力测试工具 |
gpu-burn (已编译) |
三、测试结论
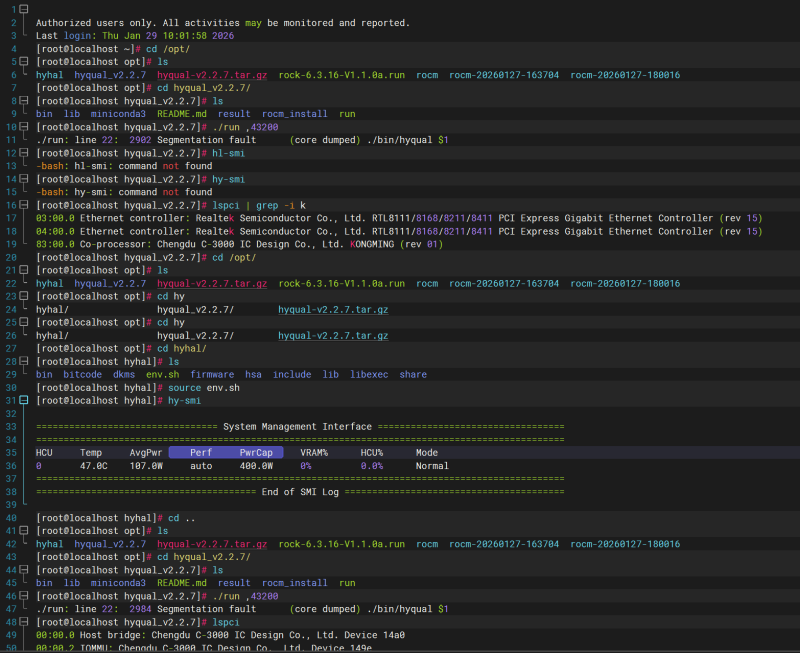
1、在 100 次重启压测的 dmesg 系统错误汇总中,高频出现了共计 406 次 pci 0000:97:xx.x: BAR 13: failed to assign [io size 0x1000] 报错 。主板在开机枚举 PCIe 设备时,无法为显卡分配 4KB 的老式 I/O 端口空间
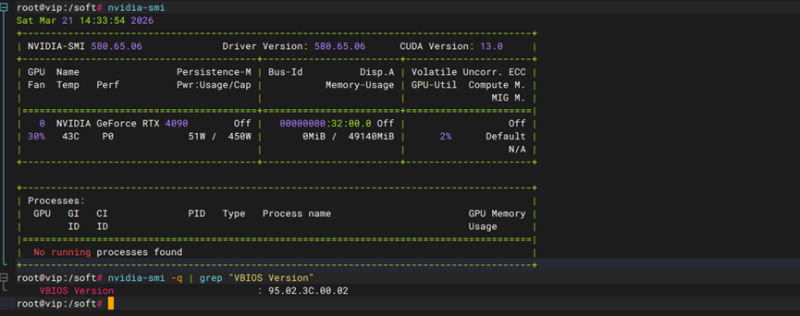
2、Dcgm压测时功耗压测未达标(75%)经确认该显卡功耗正常,只有250或260W功耗
3、NVSwitch 测试项跳过/Block(不支持,没有NVLink桥接器)
四、实际测试结果
信息检查-硬件检测
|
测试项目 |
硬件检测 |
|
测试方法 |
检查显卡外观是否由损伤或者划痕,再看金手指是否有损坏。拍照留存 |
|
预期结果 |
1. 显卡整体外观完好,无明显物理损伤、变形或严重划痕。 2. 金手指部分完整无缺,无烧毁、氧化、断脚或严重磨损痕迹。 3. 拍照留存照片清晰,能完整反映显卡外观与金手指的关键细节。 |
|
测试记录 |
显卡1
显卡2
|
|
测试结果 |
PASS |



信息检查-Linux下GPU信息查看
|
测试项目 |
Linux下GPU信息查看 |
|
测试方法 |
Lspci | grep -I nvidia 再执行lspci -vvv -s 编号 或者lspci -vvv -s 编号 | grep -i “LnkSta” |
|
预期结果 |
1. 能正确识别到 NVIDIA 显卡设备及其对应的 PCIe 总线编号(Bus ID)。 2. 能够查询到显卡的详细硬件信息(如厂商、型号、子系统 ID 等)。 3. LnkSta(Link Status)显示的当前 PCIe 速率(Speed)和总线宽度(Width)与显卡官方规格及主板插槽设计相匹配(例如:Speed 16GT/s, Width x16)。 |
|
测试记录 |
|
|
测试结果 |
PASS |

信息检查-BMC下GPU信息检查-UEFI
|
测试项目 |
BMC下GPU信息检查-UEFI |
|
测试方法 |
apt install ipmitool 执行ipmitool lan print 打开网站输入bmc然后登录账号和密码 |
|
预期结果 |
1. 通过 ipmitool lan print 获取的 BMC IP 地址能够正常 Ping 通,且能成功登录 BMC Web 管理界面。 2. 在 BMC 的“资产信息(Asset/Inventory)”、“系统信息”或专用的“GPU 状态/硬件拓扑”页面中,能够正确识别到所有已插槽的 GPU 显卡。 3. BMC 页面中显示的 GPU 硬件参数(如厂商、型号、SN 码、固件/设备 ID 等)与实际物理硬件完全一致,且硬件状态显示为“正常/OK”(无告警或缺失)。 |
|
测试记录 |
|
|
测试结果 |
PASS |
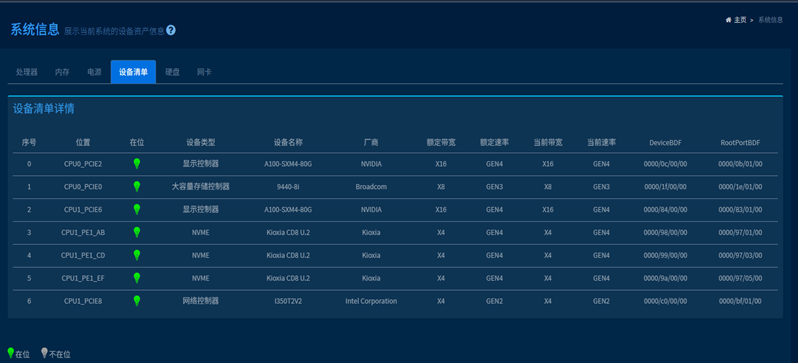
信息检查-GPU温度阈值检查
|
测试项目 |
GPU温度阈值检查 |
|
测试方法 |
执行nvidia-smi -q -d TEMPERATURE查看显卡封顶温度,然后使用gpu-burn压测,若温度超过上限温度就failed
|
|
预期结果 |
1. 执行 nvidia-smi 命令能够正常读取到 GPU 的各项温度阈值参数(如 Shutdown Limit、Slowdown Limit 等)。 2. 在使用 gpu-burn 进行满载压测期间,GPU 的最高核心温度稳定在安全范围内,未超过官方规定的上限/封顶温度(通常低于 Shutdown Limit)。 3. 压测过程中 GPU 未因高温出现异常降频(Throttling)、掉卡或系统死机重启现象,压测完成后温度能逐渐恢复至待机常温。 |
|
测试记录 |
|
|
测试结果 |
PASS |
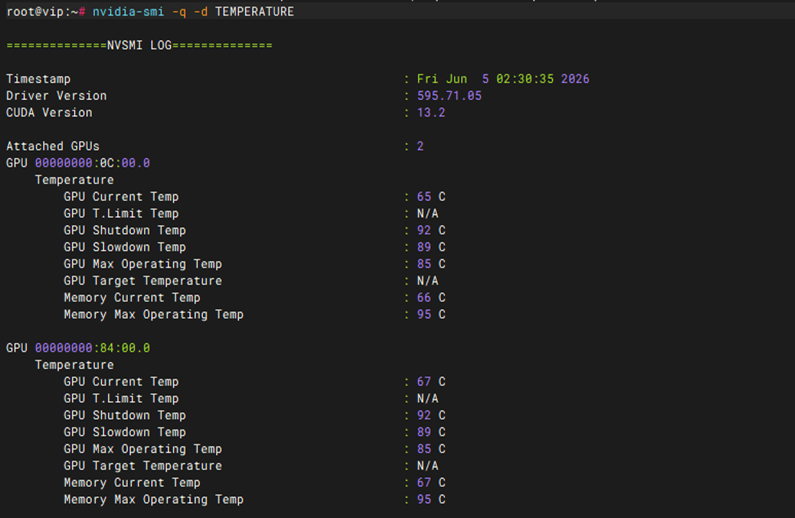
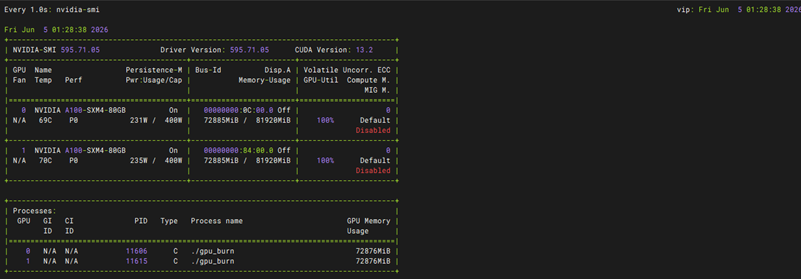
基本功能-手动-Linux下驱动及CUDA安装
|
测试项目 |
手动-Linux下驱动及CUDA安装 |
|
测试方法 |
参照知识库文档(知识库搜索英伟达显卡安装CUDA)
|
|
预期结果 |
1. NVIDIA 驱动安装成功:执行 nvidia-smi 能够正常输出 GPU 列表、显存使用情况以及正确的驱动版本号。 2. CUDA 工具链安装成功:执行 nvcc -V 能够正确输出 CUDA 编译器(nvcc)的版本信息。 3. 环境变量配置正确:系统 PATH 和 LD_LIBRARY_PATH 已正确指向 CUDA 安装路径。 |
|
测试记录 |
|
|
测试结果 |
Pass |
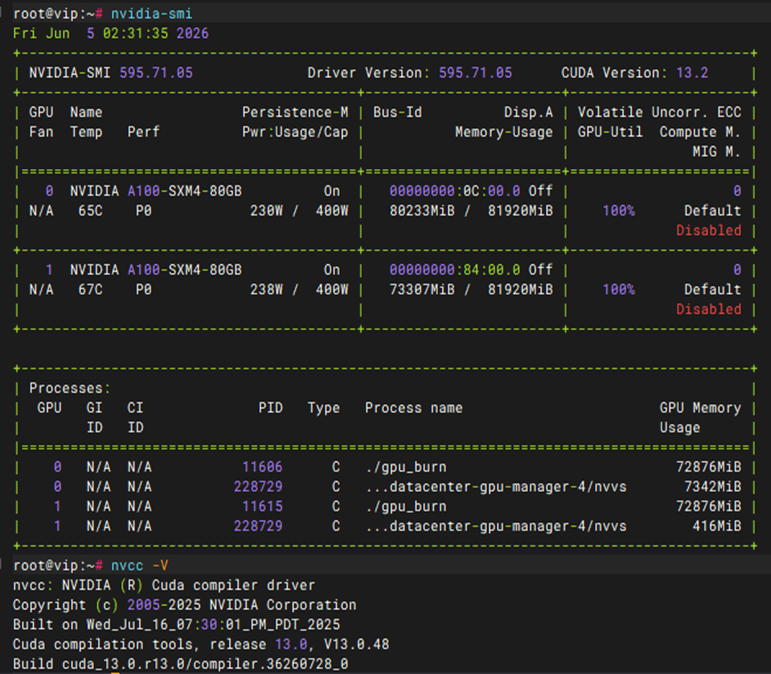
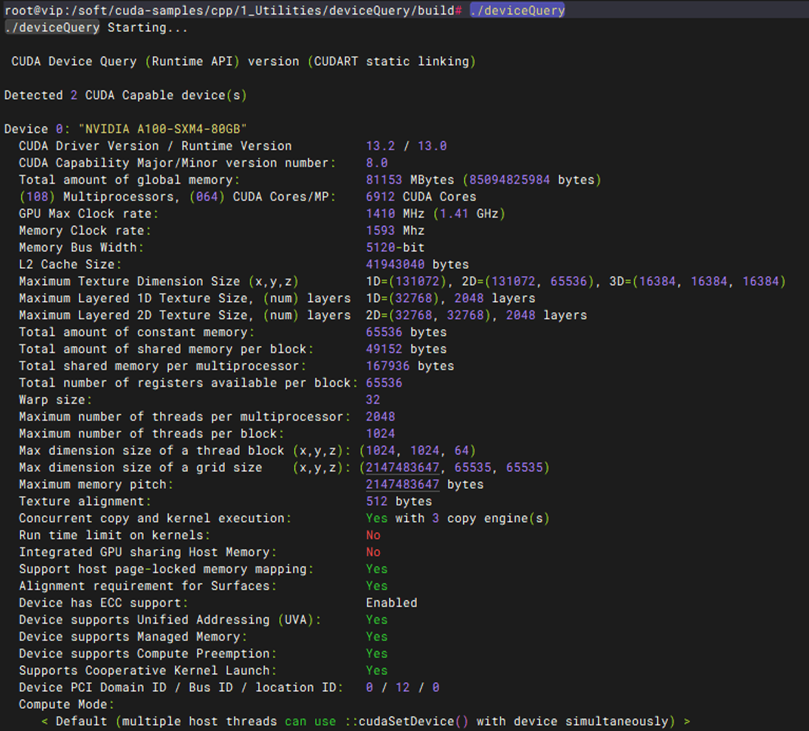
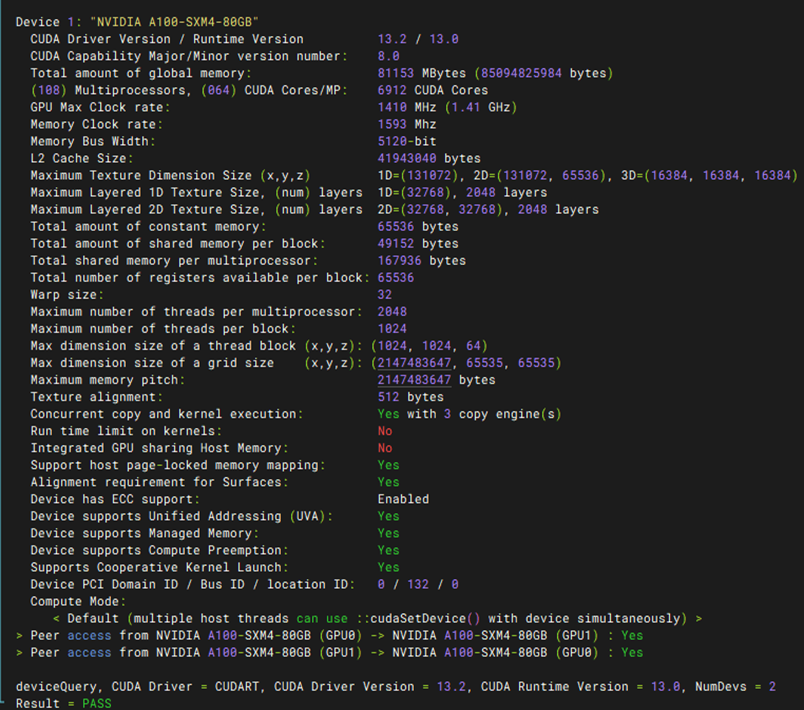
基本功能-Device Query连通性测试
|
测试项目 |
Device Query连通性测试 |
|
测试方法 |
git clone https://github.com/NVIDIA/cuda-samples.git cd cuda-samples/Samples/1_Utilities/deviceQuery mkdir build && cd build cmake .. make ./deviceQuery 另一套方案在/soft下的操作 wget https://github.com/NVIDIA/cuda-samples/archive/refs/heads/master.zip apt install -y unzip unzip master.zip mv cuda-samples-master cuda-samples cd /soft/cuda-samples/cpp/1_Utilities/deviceQuery mkdir build && cd build apt install cmake cmake .. make ./deviceQuery |
|
预期结果 |
1. 源码编译顺利完成:在执行 cmake .. 和 make 过程中,无任何报错或缺少依赖的提示,成功生成可执行文件 deviceQuery。 2. 显卡拓扑与参数正确识别:运行 ./deviceQuery 后,终端能够完整打印出当前系统中所有 GPU 的详细硬件参数(如 CUDA Driver/Runtime Version、显存大小、核心数量等)。 3. 连通性验证通过:输出结果的末尾必须明确显示 Result = PASS,证明 CUDA 运行时(Runtime)与底层 NVIDIA 驱动、GPU 硬件三者之间的通信完全正常。 |
|
测试记录 |
|
|
测试结果 |
PASS |
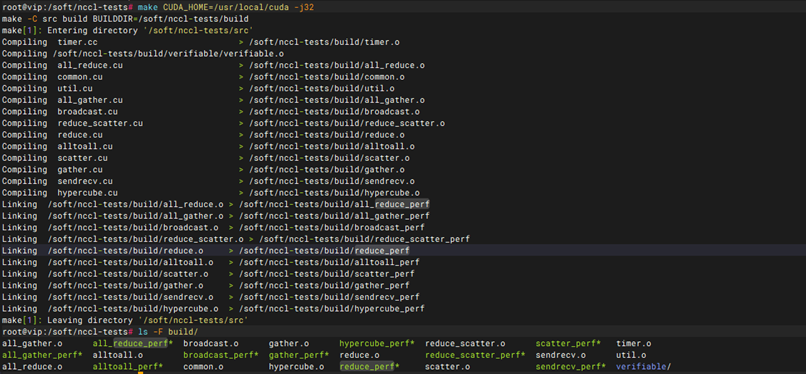
基本功能-NCCL-test测试库安装
|
测试项目 |
NCCL-test测试库安装 |
|
测试方法 |
apt update sudo apt install libnccl2 libnccl-dev -y git clone https://github.com/NVIDIA/nccl-tests.git cd nccl-tests make CUDA_HOME=/usr/local/cuda -j$(nproc) ls -F build/ 能在 build/ 目录下看到类似 all_reduce_perf, all_gather_perf, broadcast_perf 等二进制可执行文件。 |
|
预期结果 |
1. NCCL 依赖环境安装成功:系统成功安装 libnccl2 和 libnccl-dev,无依赖冲突或找不到安装包的报错。 2. 源码编译顺利完成:在指定 CUDA_HOME 路径并执行 make 编译过程中,系统能正确调用编译资源,且整个编译流程无任何报错退出(Error)。 3. 目标可执行文件成功生成:执行 ls -F build/ 后,能够在 build/ 目录下清晰看到 all_reduce_perf、all_gather_perf、broadcast_perf、reduce_perf 等高性能集合通信测试的二进制可执行文件,证明 NCCL 测试库已具备随时开展集群/多卡通信压测的能力。 |
|
测试记录 |
|
|
测试结果 |
PASS |
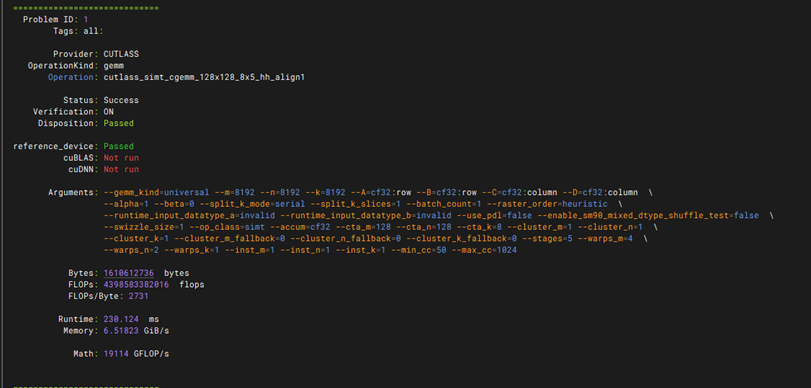
性能测试-GEMM性能测试
|
测试项目 |
GEMM性能测试 |
|
测试方法 |
git clone https://github.com/NVIDIA/cutlass.git 如果下不了就执行 git config –global http.version HTTP/1.1 cd cutlass mkdir build && cd build git config –global url.”https://gitclone.com/github.com/”.insteadOf https://github.com/ cmake .. -DCMAKE_CUDA_ARCHITECTURES=80 -DCUTLASS_NVCC_ARCHS=80 make -j$(nproc) 在/cutlass/build下执行 CUDA_VISIBLE_DEVICES=0 ./tools/profiler/cutlass_profiler –operation=gemm –m=8192 –n=8192 –k=8192 –accum_type=f16 –input_type=f16 –op_class=tensorop > gpu0.log 2>&1 &
CUDA_VISIBLE_DEVICES=1 ./tools/profiler/cutlass_profiler –operation=gemm –m=8192 –n=8192 –k=8192 –accum_type=f16 –input_type=f16 –op_class=tensorop > gpu1.log 2>&1 & 然后输入tail -f gpu0.log gpu1.log查看日志
|
|
预期结果 |
1. CUTLASS Profiler 成功编译:在指定 GPU 算力架构(如 A100 对应 -DCMAKE_CUDA_ARCHITECTURES=80)后,cmake 与 make 编译流程顺利完成,无报错并成功生成 cutlass_profiler 工具。 2. 矩阵乘法压测并发启动正常:通过 CUDA_VISIBLE_DEVICES 分别指定卡号,对应的 GEMM 压测进程能正常在后台并发调起,日志文件(gpu0.log、gpu1.log)能实时写入,无由于显存不足(OOM)导致的进程直接退出。 3. Tensor Core 算子调用及数据验证成功:通过 tail -f 查看日志,程序成功匹配并调度当前架构对应的 Tensor Core 硬件算子(tensorop),多轮迭代运算中无计算数据错误,未发生因硬件不稳定导致的核心挂起。 4. 浮点算力(Tflops)达标:测试报告中最终输出的 GEMM 性能数据里,核心指标 Runtime(运行时间) 保持平稳,且 GFLOPs 或 TFLOPs(吞吐量/算力表现)达到或接近该型号 GPU 在 FP16(半精度)下官方标称的理论峰值,软硬件矩阵计算效能达标。 |
|
测试记录 |
显卡1:
显卡2:
|
|
测试结果 |
PASS |
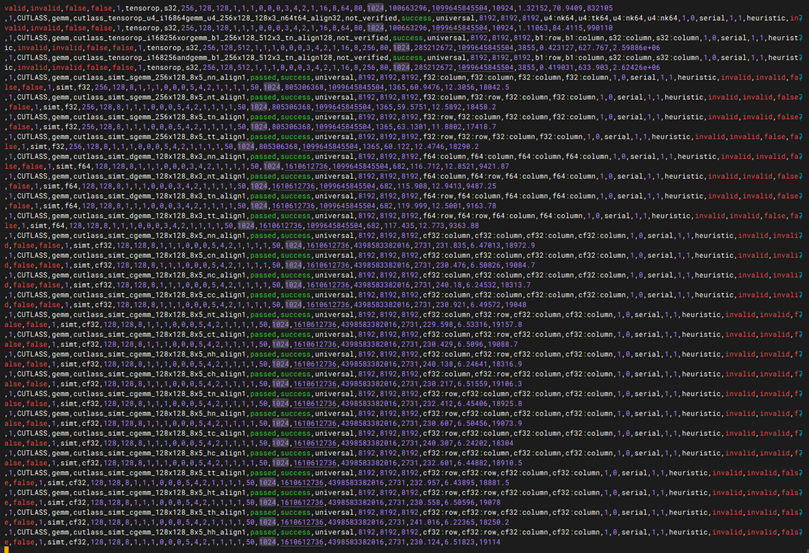
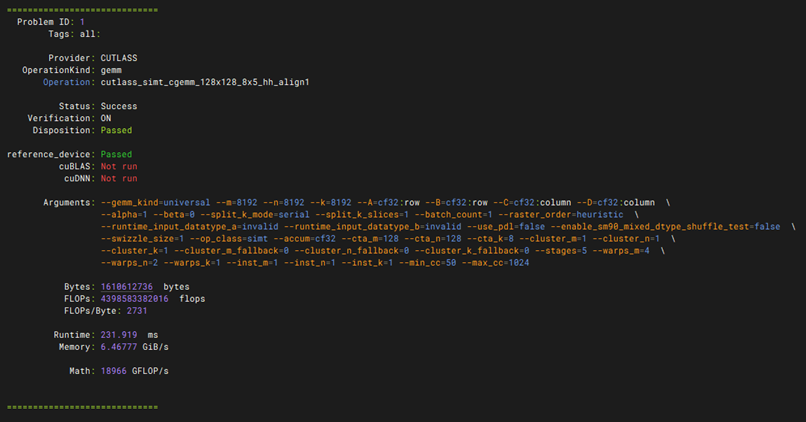
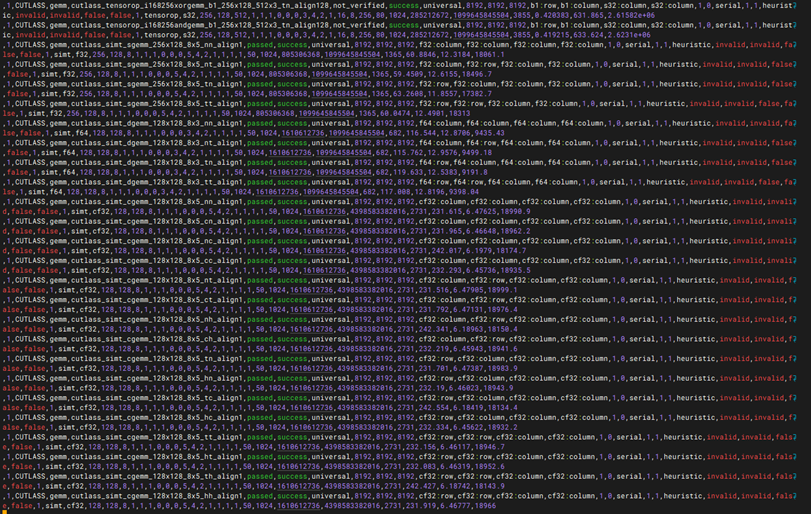
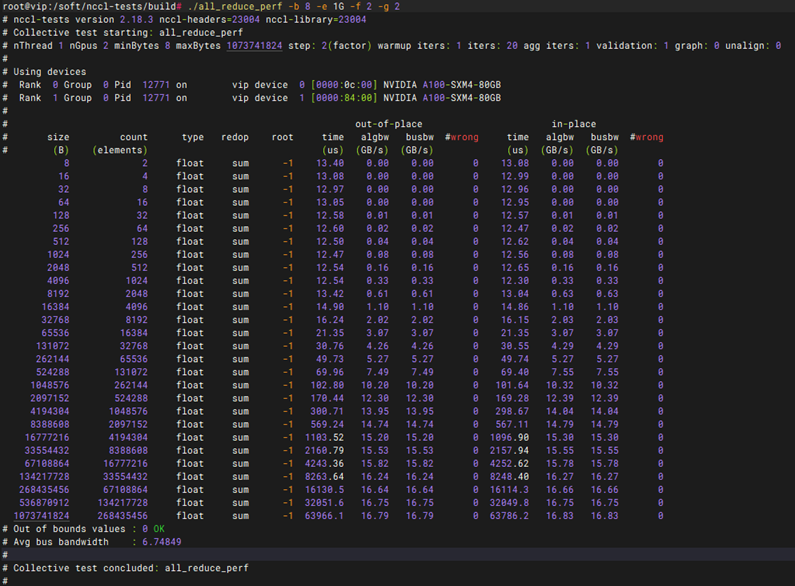
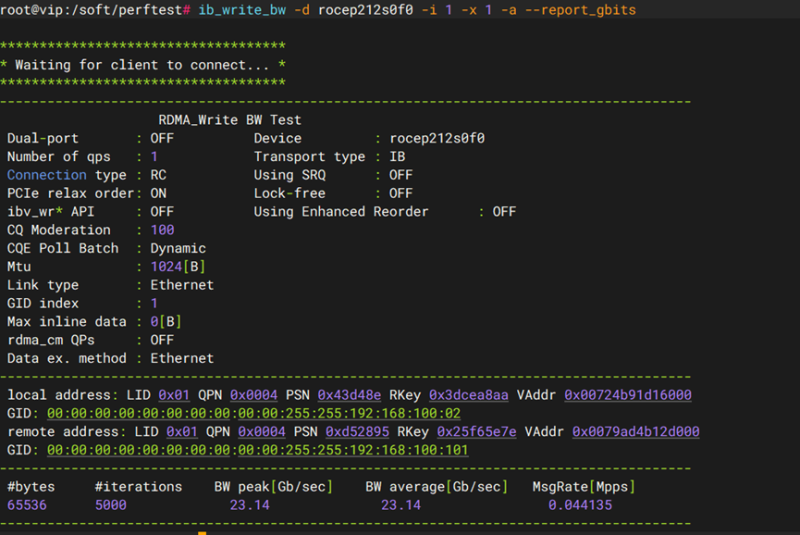
性能测试-bandwidth带宽性能测试
|
测试项目 |
bandwidth带宽性能测试 |
|
测试方法 |
apt install -y build-essential cmake libboost-program-options-dev git clone https://github.com/NVIDIA/nvbandwidth.git cd nvbandwidth cmake . make -j ./nvbandwidth
|
|
预期结果 |
1. 测试工具编译成功:在安装完基础依赖后,执行 cmake . 和 make -j 过程顺利,无编译报错,成功生成 nvbandwidth 可执行文件。 2. 硬件拓扑与性能数据正确输出:运行 ./nvbandwidth 后,终端能够正常识别系统中的所有 GPU,并输出结构化的带宽性能矩阵(如 Device to Device Bandwidth Matrix)。 3. 带宽与时延指标符合预期:各 GPU 节点之间的双向/单向带宽吞吐量(单位通常为 GB/s)以及访问时延(单位为 ns)均达到或接近该机型(如 PCIe Gen4/Gen5 或 NVLink 架构)的官方理论基准值,无异常性能跌落。 |
|
测试记录 |
|
|
测试结果 |
NVSwitch未测试为block |
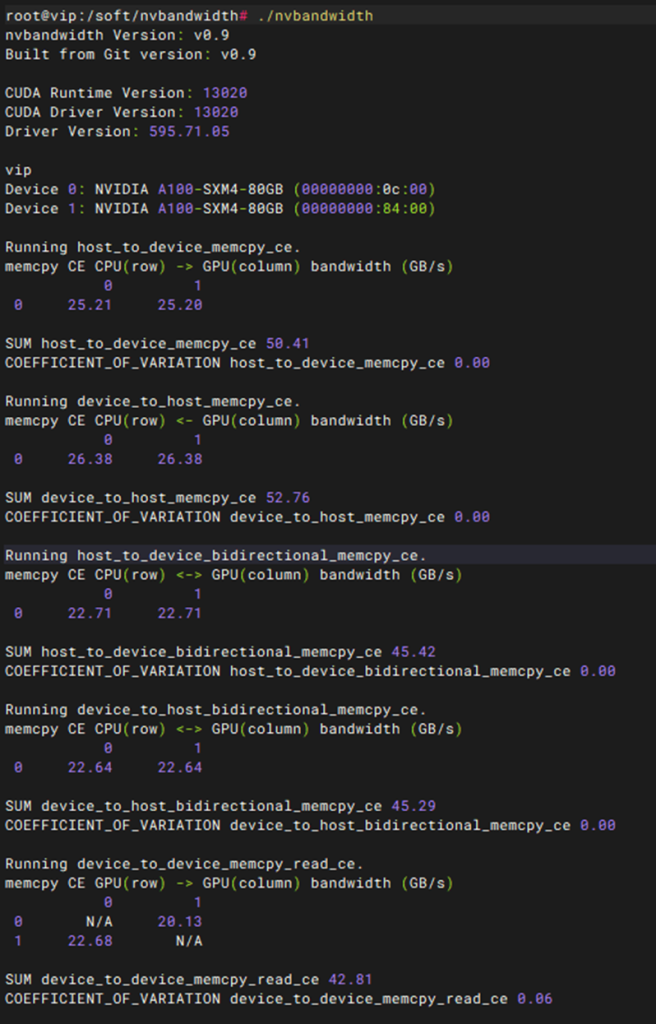
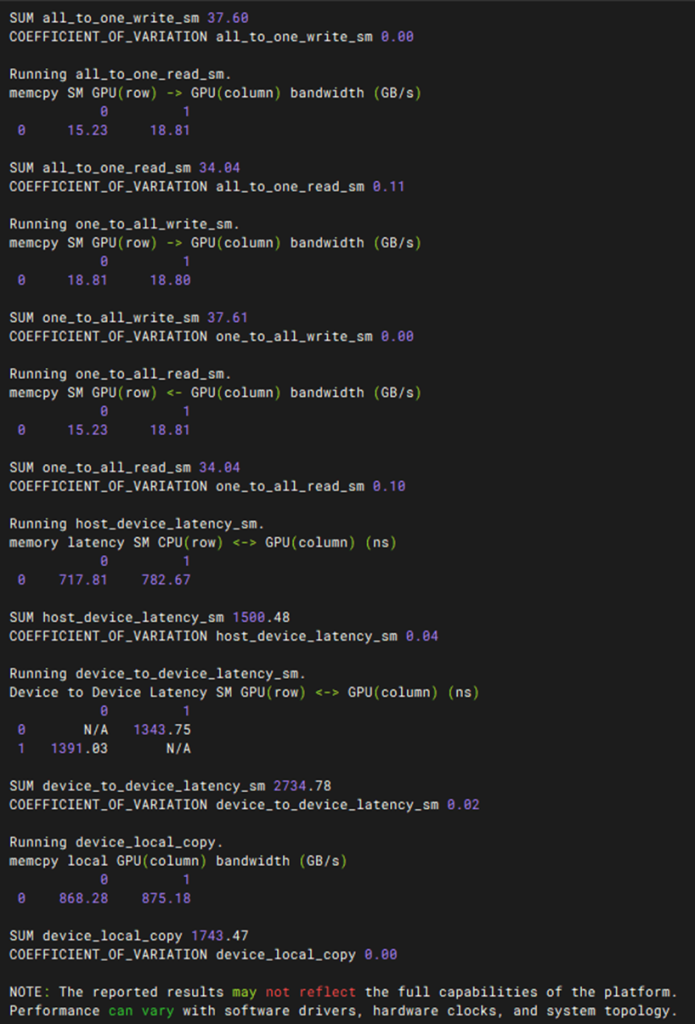
性能测试-P2P性能测试
|
测试项目 |
P2P性能测试 |
|
测试方法 |
git clone https://github.com/NVIDIA/cuda-samples.git cd cuda-samples mkdir build cd build apt install cmake cmake .. make -j$(nproc) find / -name p2pBandwidthLatencyTest 例子: root@vip:~/cuda-samples/build# find / -name p2pBandwidthLatencyTest /root/cuda-samples/Samples/5_Domain_Specific/p2pBandwidthLatencyTest /root/cuda-samples/build/Samples/5_Domain_Specific/p2pBandwidthLatencyTest /root/cuda-samples/build/Samples/5_Domain_Specific/p2pBandwidthLatencyTest/p2pBandwidthLatencyTest p2pBandwidthLatencyTest/p2pBandwidthLatencyTest这个就是 然后cd /root/cuda-samples/build/Samples/5_Domain_Specific/p2pBandwidthLatencyTest 执行./p2pBandwidthLatencyTest 前面是安装了那个cuda-samples包的所以直接执行./p2pBandwidthLatencyTest然后根据实际来看,我这里是/soft/cuda-samples/cpp/5_Domain_Specific/p2pBandwidthLatencyTest下,cd进入后执行三个命令 mkdir -p build && cd build cmake .. make ./p2pBandwidthLatencyTest 如果没有安装就执行上面的安装步骤。 |
|
预期结果 |
1. 测试工具成功编译:在 p2pBandwidthLatencyTest 源码目录下执行 cmake .. 和 make 顺利完成,无报错并成功生成对应的可执行程序。 2. P2P 硬件支持状态正常:运行 ./p2pBandwidthLatencyTest 后,输出的 P2P 启用矩阵(P2P Connectivity Matrix)中,支持 P2P 的 GPU 节点间对等访问状态均显示为 1(Yes),证明硬件及驱动层已正常开启点对点直连。 3. 带宽与时延数据合规:成功打印出“带 P2P 开启”与“不带 P2P 开启”两种状态下的单向/双向带宽矩阵(MB/s)与时延矩阵(us)。其中,开启 P2P 后的传输带宽与延迟均需符合该服务器物理链路(如 PCIe 直连或 NVLink 拓扑)的官方基准标准,无明显的性能瓶颈。 |
|
测试记录 |
|
|
测试结果 |
PASS |
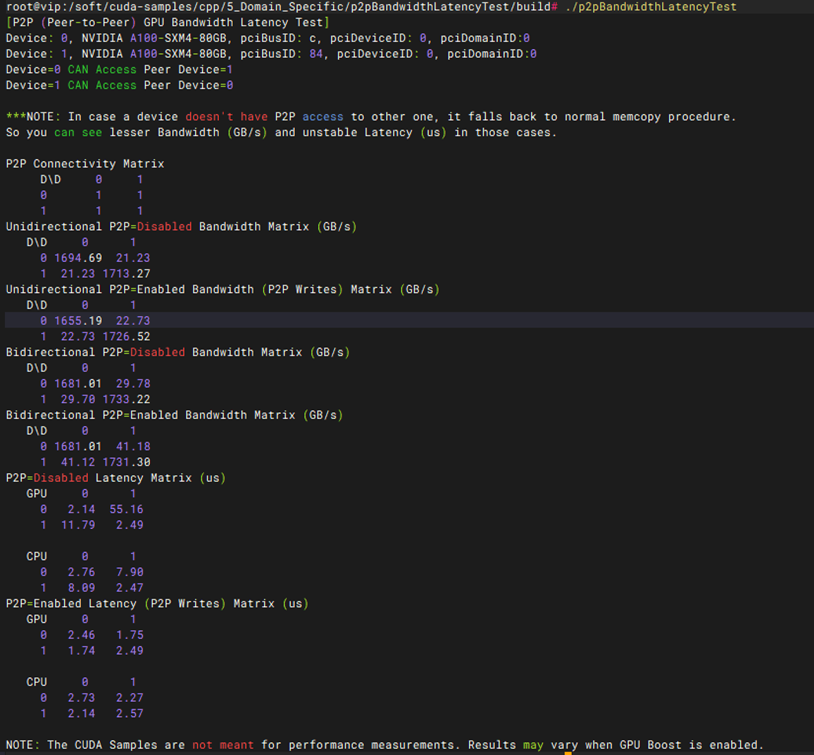
性能测试-NCCL alltoall带宽性能测试
|
测试项目 |
NCCL alltoall带宽性能测试 |
|
测试方法 |
需要安装nccl-test库先 再执行cd nccl-tests/和cd build再执行 ./alltoall_perf -b 8 -e 1G -f 2 -g 2(这里的2是显卡数量)
|
|
预期结果 |
1. NCCL 进程顺利初始化:执行 ./alltoall_perf 后,测试程序能够正常初始化 NCCL 环境(NCCL info init ok),成功识别并绑定指定的 GPU 数量(-g 2),无通信握手失败或超时报错。 2. 迭代测试数据完整输出:程序成功在指定的数据量范围(从 8 字节 -b 8 到 1G 字节 -e 1G,以 2 倍 -f 2 递增)内完成多轮 All-to-All 集合通信测试,中途无中断。 3. 带宽指标达标且稳定:在测试报告的输出表格中,大包(如数兆至数百兆字节)阶段的“总线带宽(Bus BW)”趋于稳定,且测得的平均带宽数值达到或接近当前服务器架构下的理论峰值(如双卡间 PCIe 4.0/5.0 或 NVLink 的预期带宽),且 out-of-place 校验结果无数据错乱(显示为 0 errors)。 |
|
测试记录 |
|
|
测试结果 |
PASS |
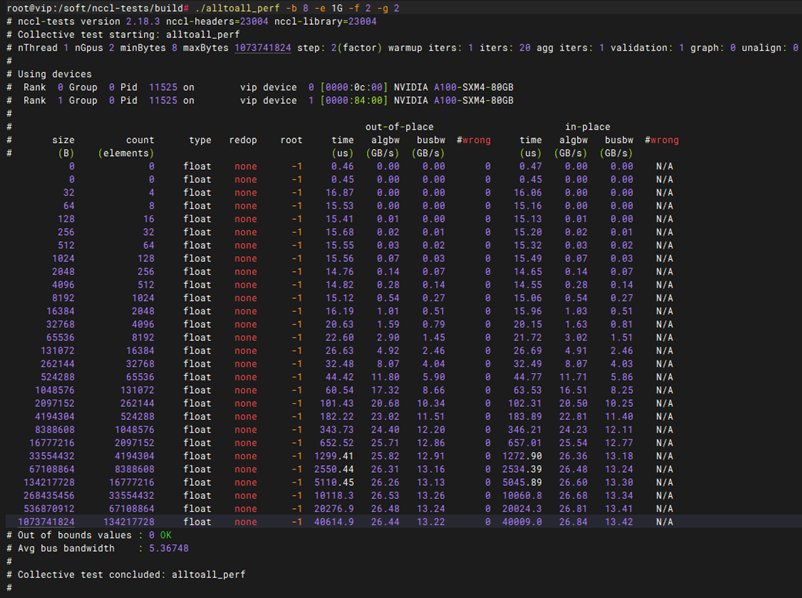
性能测试-NCCL all_reduce带宽性能测试
|
测试项目 |
NCCL all_reduce带宽性能测试 |
|
测试方法 |
需要安装nccl-test库先
./build/all_reduce_perf -b 8 -e 1G -f 2 -g 2 (2是显卡数量)
|
|
预期结果 |
1. NCCL 拓扑成功初始化:执行 ./all_reduce_perf 后,测试程序能够顺利拉起 NCCL 环境,成功识别并绑定系统中的 2 张 GPU(-g 2),无通信握手失败、网络超时(Timeout)或掉卡报错。 2. 集合通信测试连续稳定:测试程序能够稳定地在指定数据量区间(8B 至 1GB,以 2 倍递增)内连续完成多轮 All-Reduce 规约操作,大包测试阶段未出现显存溢出(OOM)或进程挂起。 3. 规约带宽达标且数据零报错:测试输出表格中大包阶段的“总线带宽(Bus BW)”达到或接近当前服务器架构下的理论峰值(如双卡间 PCIe 通道或 NVLink 拓扑的官方推荐带宽值);同时,每轮迭代的校验错误数(Errors 列)必须严格为 0,证明多卡通信及数据规约计算 100% 准确。 |
|
测试记录 |
|
|
测试结果 |
pass |
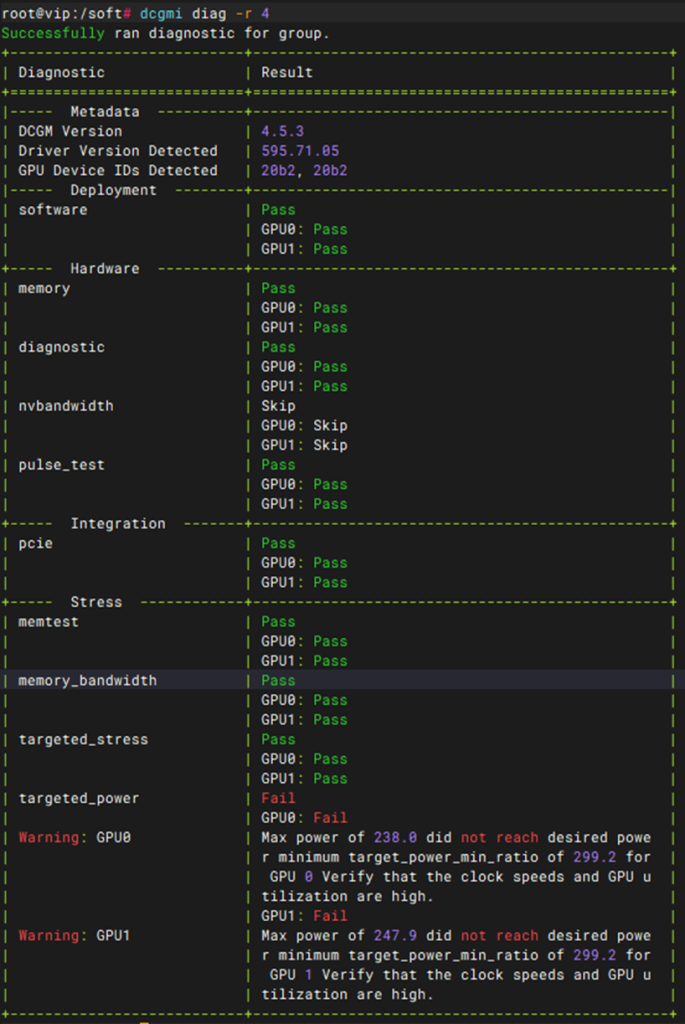
压力测试-DCGM压力测试
|
测试项目 |
DCGM压力测试 |
|
测试方法 |
根据实际系统来 wget https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2404/x86_64/datacenter-gpu-manager-4-cuda13_4.5.3-1_amd64.deb 等会时间再执行 systemctl stop apt-daily.service systemctl stop apt-daily-upgrade.service systemctl stop apt-daily.timer systemctl stop apt-daily-upgrade.timer pkill -9 -f apt.systemd.daily pkill -9 -f apt-check pkill -9 -f dpkg 然后执行: dpkg -i datacenter-gpu-manager-4-core_4.5.3-1_amd64.deb dpkg -i datacenter-gpu-manager-4-cuda13_4.5.3-1_amd64.deb # 刷新 systemd 缓存 systemctl daemon-reload
# 启用并启动服务 systemctl enable nvidia-dcgm systemctl start nvidia-dcgm
# 确认服务状态 (应该是 Active: active (running)) systemctl status nvidia-dcgm nvidia-smi -pm 1开启持久化 dcgmi diag -r 4
|
|
预期结果 |
1. DCGM 软件正常安装与拉起:两个 .deb 组件(core 与 cuda13)顺利安装完成,执行 systemctl status nvidia-dcgm 后,服务状态明确显示为 Active: active (running)。 2. 显卡持久化模式成功开启:执行 nvidia-smi -pm 1 提示开启成功(Enabled),无权限或驱动报错。 3. 显卡深度诊断(Level 4)顺利通过:执行 dcgmi diag -r 4 压测诊断程序能够完整跑完所有测试子项(如软件环境、PCIe、显存、功耗、热耗、计算压力等)。 4. 最终诊断报告合格:诊断结果输出中,各项检测指标(如 Deployment、Hardware、Integrity、Stress)的 Status 必须全部显示为 Success 或 PASS,证明服务器内的 GPU 软硬件环境在极高负载下表现完全健康、无潜在故障风险。 |
|
测试记录 |
|
|
测试结果 |
显卡功耗达不到75%,nvbandwidth没有nvlink连接器视为为block。 |
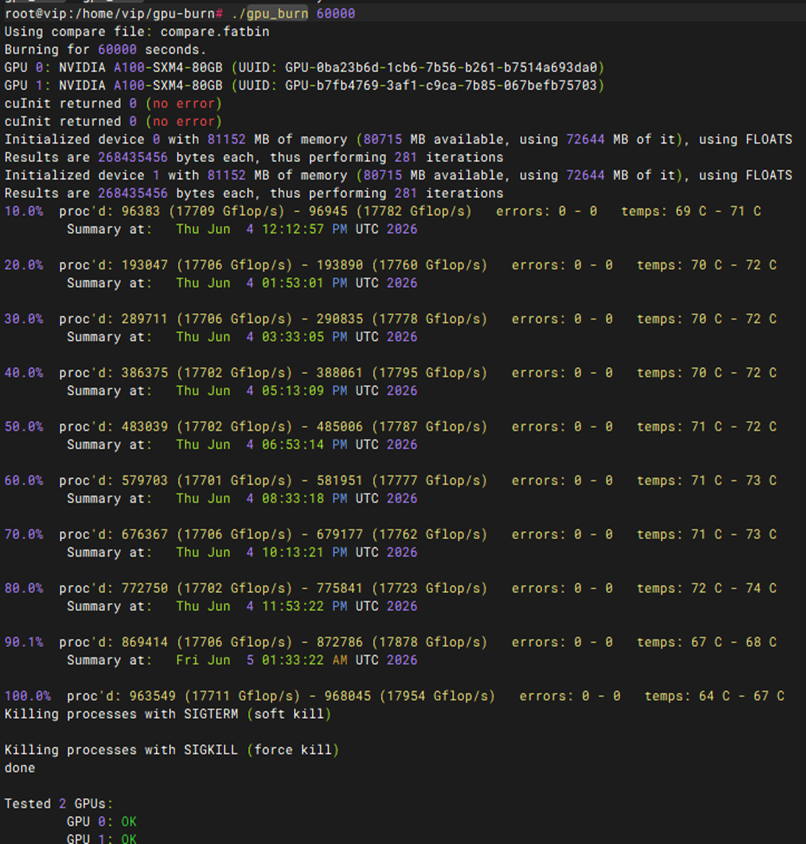
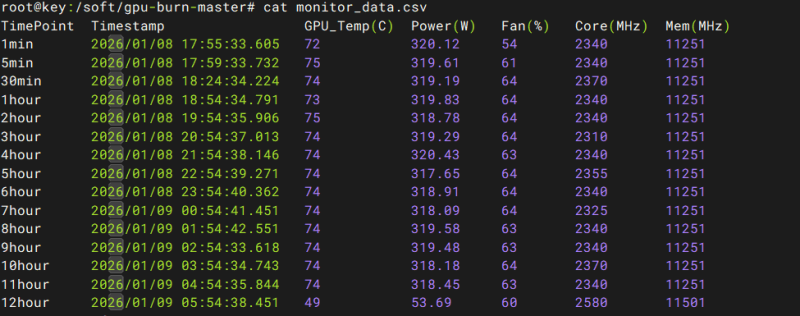
压力测试-GPU Burn测试(12h)
|
测试项目 |
GPU Burn测试(12h) |
|
测试方法 |
gpu-burn-master.zip与脚本在nas.yanxu.store网站的/homes/stars/Backup/STARS/E/测试相关/测试工具/显卡测试下的gpu-burn-master.zip与gpu-burn.sh 上传压测软件gpu-burn-master.zip和脚本到/soft目录下 执行unzip gpu-burn-master.zip 然后执行cd gpu-burn-master 执行make 执行脚本./gpu-burn.sh 输入想压测的时间 |
|
预期结果 |
1. 压测环境成功构建:gpu-burn 源码通过 make 编译顺利完成,无报错并成功生成压测主程序。 2. 极限高负载持续运行稳定:在指定的 12 小时满载压测周期内,测试程序及底层 GPU 硬件表现出极高的稳定性。中途无程序闪退、无内核报错(如 XID 错误)、无显卡掉线(掉卡)以及无系统死机或自动重启现象。 3. 散热与功耗控制良好:压测期间,各 GPU 核心温度及显存温度在风扇全速运转下均稳定维持在安全阈值(Slowdown Limit)以内,未触发过热保护性降频,各卡功耗持续维持在满载设计功率上下。 4. 压测计算结果 100% 准确:压测时间截止后,程序能够顺利完成最后一轮迭代并正常退出,终端或日志最终明确输出 100% pass 或 OK(未发现任何计算矩阵的浮点数算力错误)。 |
|
测试记录 |
|
|
测试结果 |
PASS |
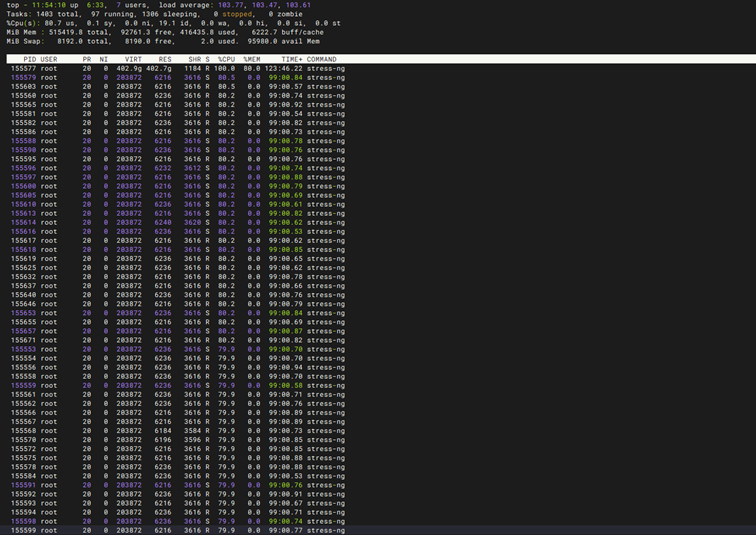
压力测试-整机压力测试(12h)
|
测试项目 |
整机压力测试(12h) |
|
测试方法 |
把hw_test\stability\stress下的run.sh、net_stress.sh、mem_stress.sh、file_sys_stress.sh、disk_stress.sh、cpu_stress.sh传到任意目录下,然后执行./run.sh然后选择想要压测的功能再选择12h然后显卡使用gpu-burn压起来12小时,执行uptime |
|
预期结果 |
1. 测试框架及子脚本顺利联动:run.sh 能够成功拉起 CPU、内存、文件系统、磁盘、网络等所有子压测脚本,同时配合 gpu-burn 成功实现软硬件全栈满载联合压测。 2. 整机供电与电气稳定性达标:在 CPU 和 GPU 同时拉满的“峰值功耗(Peak Power)”状态下持续运行 12 小时,服务器主板供电、电源模块(PSU)无异常保护,系统无断电、无闪退、无自动重启。 3. 散热与风道环境通过考验:在整机内部发热量达到极限的情况下,各核心部件的温度稳定在安全阈值内,未触发任何硬件级别的热限保护(Thermal Throttling)或降频。 4. 软硬件系统运行零报错:12 小时测试截止后,各子压测进程正常退出。检查操作系统内核日志(dmesg / syslog),无 CPU 物理错误(MCE)、无显卡硬件错误(XID)、无内存硬件纠错/无法纠错(ECC Error)、无网络丢包或 I/O 读写超时,整机各项功能表现完全稳定。 |
|
测试记录 |
|
|
测试结果 |
本次测试只压测了cpu、内存、显卡,硬盘及网络未加入本次测试中 |

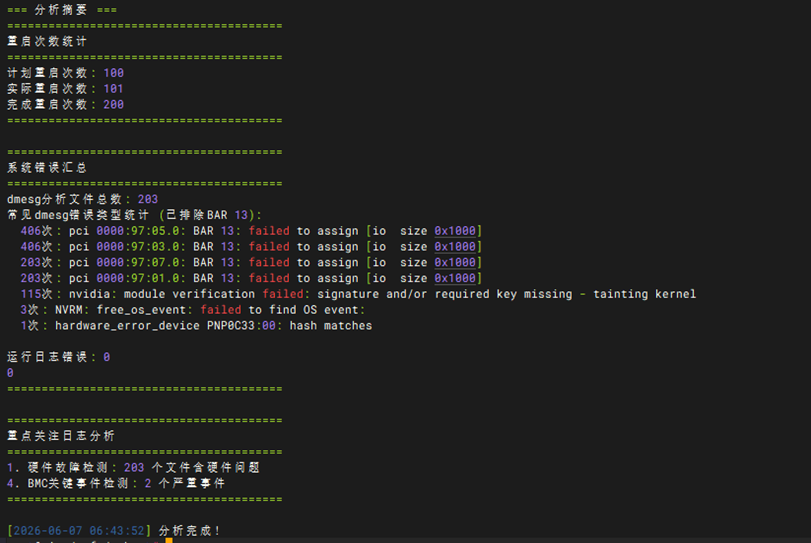
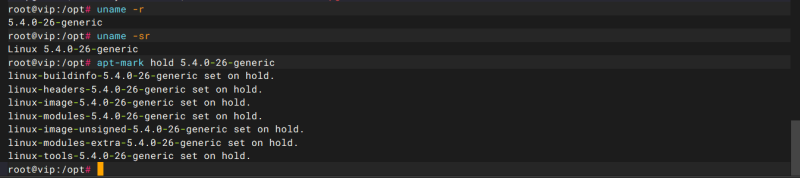
压力测试-Linux下reboot测试(100次)
|
测试项目 |
Linux下reboot测试(100次) |
|
测试方法 |
执行hw_test\stability\reboot下的脚本,先执行init_reboot_power_cycle.sh -n 100 然后执行collect_reboot_power_cycle_ubuntu_update.sh 等待重启,最后执行analyze_reboot_logs_simple.sh 查看报错原因 |
|
预期结果 |
1. 自动化重启脚本循环触发正常:init_reboot_power_cycle.sh 脚本能够准确计数,并在系统每次开机后自动、稳定地拉起下一次重启任务,中途无脚本中断或进程丢失。 2. 系统引导及硬件加载 100% 成功:在长达 100 次的连续重启过程中,服务器每次均能顺利通过 BIOS/UEFI 自检,成功引导并进入 Linux 操作系统。期间无死机(Hang死)、无卡在 BIOS 界面、无无法识别到启动盘的故障。 3. 硬件资产在冷热启动下无丢失:在每次重启后,系统内核及带外管理(BMC)均能完整、正确地识别到整机全部物理资产(如 CPU 核心数、内存总容量、所有显卡/GPU 数量、全部存储网卡等),无“掉卡”或硬件丢失现象。4. 日志分析结果完全合格(PASS):执行 analyze_reboot_logs_simple.sh 后,最终分析报告无任何报错提示。检查系统内核日志(dmesg),无硬件初始化失败错误或严重的 PCI-E 异常丢包报错。 |
|
测试记录 |
|
|
测试结果 |
主板在PCIe 资源分配硬盘时出现BAR 13 报错 |



暂无评论内容