

|
提交时间 |
测试内容 |
测试工程师 |
审核人 |
|
2026.1.10 |
1. TW G620X4平台&8张 NVIDIA RTX 6000DGPU 在特定硬件配置条件下的稳定性测试. 2 NVIDIA RTX 6000DGPU 功能信息检查. 3. NVIDIA RTX 6000DGPU 热功耗测试. 4. NVIDIA RTX 6000DGPU 性能测试. 5.CPU 与内存性能测试. |
孙程浩 陈旺 |
高云辉 |
|
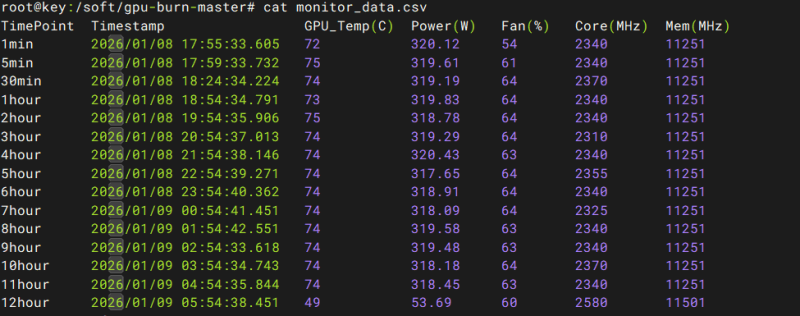
RTX 6000D linux下12小时满压测试结果 |
|||||
|
硬件编号 |
负载使用率 |
平均算力 |
峰值温度 |
测试时长 (累计) |
总算力 |
|
GPU 0 |
100% |
60.31 |
85°C |
12 Hours |
498.82 (12h) |
|
GPU 1 |
100% |
61.34 |
85°C |
12 Hours |
498.80 (12h) |
|
GPU 2 |
100% |
62.45 |
85°C |
12 Hours |
498.65 (12h) |
|
GPU 3 |
100% |
62.81 |
85°C |
12 Hours |
475.30 (12h) |
|
GPU 4 |
100% |
62.77 |
85°C |
12 Hours |
475.30 (12h) |
|
GPU 5 |
100% |
61.98 |
85°C |
12 Hours |
475.30 (12h) |
|
GPU 6 |
100% |
62.85 |
86°C |
12 Hours |
475.30 (12h) |
|
GPU 7 |
100% |
62.91 |
87°C |
12 Hours |
475.30 (12h) |
|
使用bandwidthTest对GPU进行PCIE带宽测试测试结果 |
|||
|
GPU Mode (Bus ID) |
Host to Device Bandwidth (GB/s) |
Device to Host Bandwidth (GB/s) |
Device to Device Bandwidth (GB/s) |
|
GPU0 |
56.45 |
48.28 |
639.18 |
|
GPU1 |
56.44 |
48.82 |
639.18 |
|
GPU2 |
56.43 |
48.06 |
638.7 |
|
GPU3 |
56.43 |
49.25 |
638.75 |
|
GPU4 |
56.43 |
54.72 |
638.7 |
|
GPU5 |
56.43 |
50.18 |
639.18 |
|
GPU6 |
56.44 |
55.67 |
639.18 |
|
GPU7 |
56.42 |
51.35 |
638.75 |
|
使用 cuda 自带的 busGrind 测试,测试结果如下(8根内存条件下进行测试). |
||
|
GPU 编号 (ID) |
平均带宽 (Avg Bandwidth, GB/s) |
平均延迟 (Avg Latency, μs) |
|
GPU 0 |
34.23 |
0.84 |
|
GPU 1 |
33.51 |
0.84 |
|
GPU 2 |
32.89 |
0.84 |
|
GPU 3 |
32.6 |
0.84 |
|
GPU 4 |
33.26 |
0.84 |
|
GPU 5 |
33.86 |
0.84 |
|
GPU 6 |
33.68 |
0.84 |
|
GPU 7 |
34.14 |
0.84 |
|
在 TW G620X4平台上使用RTX6000D基于 Pytorch 框架运行深度学习ResNet101 模型,并基于 ImageNet(3x224x224)数据集相同样本数进行运算,测试 1 卡、2 卡、4 卡和8 卡条件下每秒运算图片数量.同时针对 1 卡、2 卡、 4 卡和8 卡的扩展测试计算其加速比 |
||||
|
项目 |
NVIDIA GPU 卡 |
|||
|
任务类型 |
图像分类 |
|||
|
数据集 |
ImageNet(3x224x224) |
|||
|
卡数量 |
1 卡 |
2 卡 |
4 卡 |
8 卡 |
|
显存(百分比) |
99% |
99% |
99% |
99% |
|
每秒运算图片数量 |
4179.27 |
8,327.56 |
16,654.38 |
33,309.62 |
|
加速比 |
1.00 (基准) |
1.993 |
3.985 |
7.970 |
|
FIO硬盘测试数据 |
|||||
|
测试阶段 |
测试项目 (Block Size) |
测试类型 |
测试指标 |
测试数值 |
换算单位 (约) |
|
1月4日 |
顺序写 (128K) |
吞吐量/带宽 |
4,945,577 KB/s |
4,829 MB/s |
4.72 GB/s- |
|
2月4日 |
顺序读 (128K) |
吞吐量/带宽 |
7,396,465 KB/s |
7,223 MB/s |
7.05 GB/s- |
|
3月4日 |
随机写 (4K) |
每秒读写次数 |
1,236,326 IOPS |
约 4,829 MB/s- |
123.6 万 IOPS |
|
4月4日 |
随机读 (4K) |
每秒读写次数 |
1,889,270 IOPS |
约 7,380 MB/s- |
188.9 万 IOPS |
|
使用Intel Xeon Gold 6530CPU在 TW G620X4平台上运行 sysbench 基准测试工具,基于最大到 20000的素数进行 CPU 计算,测试在单线程以及多线程条件下每秒的计算速度 |
||
|
CPU 线程数 |
每秒计算速度 |
平均计算延迟(ms) |
|
1 |
894.5 |
1.12 |
|
8 |
7128.53 |
1.12 |
|
16 |
14251.26 |
1.12 |
|
32 |
28518.28 |
1.12 |
|
48 |
40196.16 |
1.19 |
|
64 |
36209.89 |
1.77 |
|
128 |
59,003.06 |
2.17 |
|
MLC 内存测试数据表 |
||
|
注入延迟 (Inject Delay) |
访问延迟 Latency (ns) |
吞吐带宽 Bandwidth (MB/sec) |
|
0 |
454.67 |
237,379.90 |
|
2 |
497.3 |
237,789.90 |
|
8 |
439.77 |
239,108.30 |
|
15 |
439.69 |
238,117.50 |
|
50 |
398.16 |
234,450.80 |
|
100 |
392.27 |
214,083.70 |
|
200 |
162.67 |
112,425.20 |
|
300 |
156.64 |
79,091.50 |
|
400 |
164.92 |
61,841.70 |
|
500 |
179.58 |
49,848.30 |
|
700 |
185.2 |
35,898.60 |
|
1000 |
161.05 |
25,445.90 |
|
1300 |
179.56 |
19,397.60 |
|
1700 |
188.79 |
15,088.10 |
|
2500 |
175.4 |
10,284.50 |
|
3500 |
173.35 |
7,533.40 |
|
5000 |
214.26 |
5,253.00 |
|
9000 |
170.4 |
3,125.00 |
|
20000 |
167.87 |
1,650.00 |
|
NUMA 内存带宽矩阵 (MB/sec) |
||
|
NUMA node |
0 |
1 |
|
0 |
126527.7 |
84695.9 |
|
1 |
85782.3 |
131341.5 |
|
内存延迟测试 |
||
|
项目 (Item) |
数值 (Value) |
单位 (Unit) |
|
基础频率时钟周期 |
230.1 |
Cycles |
|
缓冲区大小 |
2000 |
MiB |
|
空闲延迟 |
109.6 |
ns |
1、测试目的
关于该测试报告主要有以下几个测试目的:
TW G620X4平台&NVIDIA RTX 6000DGPU 在特定硬件配置条件下的稳定性验证.
验证 GPU 等部件的功能信息.
验证系统及部件的热功耗.
性能验证.NVIDIA RTX 6000DGPU
CPU 与内存性能验证.
硬盘性能验证
2、测试硬件配置
TW G 6 2 0 X 4 平台硬件配置参见下表:
|
部件 |
配置 |
数量 |
|
服务器 |
TW G620X4 |
1 |
|
处理器 |
Intel Xeon Gold 6530CPU |
2 |
|
Memory |
三星32GDDR5 4800 REG 内存 |
8 |
|
硬盘 |
华为ES3500P V6 3.84T U.2NVME SSD |
2 |
|
GPU |
NVIDIA RTX 6000DGPU |
8 |
|
风扇 |
整机 |
1 |
|
网卡 |
东大网卡 FM——–NHI350AM2-T2 |
1 |
|
电源 |
整机 |
1 |
3、测试软件配置
TW G620X4平台及部件软件配置参见下表:
|
服务器 |
TW G620X4 |
|
操作系统及内核版本 |
Ubuntu 24.04.3 LTS |
|
BIOS 版本 |
00.02.00 |
|
BMC 版本 |
0.01.04 |
|
GPU 固件版本 |
98.02.81.00.02 |
|
GPU 驱动版本 |
580.65.06 |
|
CUDA 版本 |
13.1 |
|
压力测试软件 |
gpu_burn |
|
网卡驱动版本 |
Usb接口 |
4、服务器示意图
|
|
|
|
平台&GPU 卡安装示意图 |
GPU 卡安装示意图 |


5、测试项目
5.1 TW G620X4&8张6000D GPU 在特定硬件配置下的系统稳定性测试
5.1.1 CPU&MEM&GPU 卡压力测试
此项测试是利用 Stress 压力测试工具与 gpu_burn 工具,将系统与GPU 卡运行在满负载条件下测试了 3*24h.经测试系统在满负载状态下(环境温度:26℃~35℃),风墙风扇默认设置为“ 自动模式 ”,其对应 Sensor 温度低于临界值,测试结果无异常.
1).以下为 CPU&MEM 在压力测试时的使用率信息.
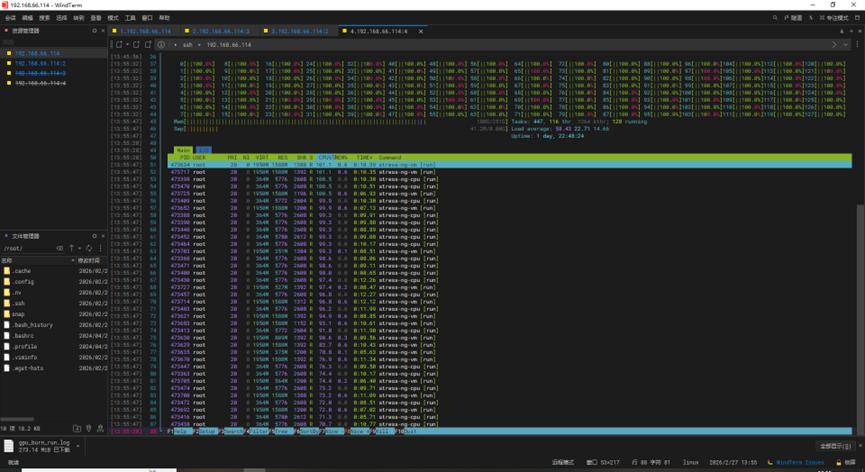
2).以下为(环温 ℃ , 风扇模式为自动模式)Geforce 卡在压力测试时的功耗、温度、使用率等信息.显卡运行状态正常,散热&功耗正常.
linux下12小时满压测试结果
1分钟-3小时测试结果
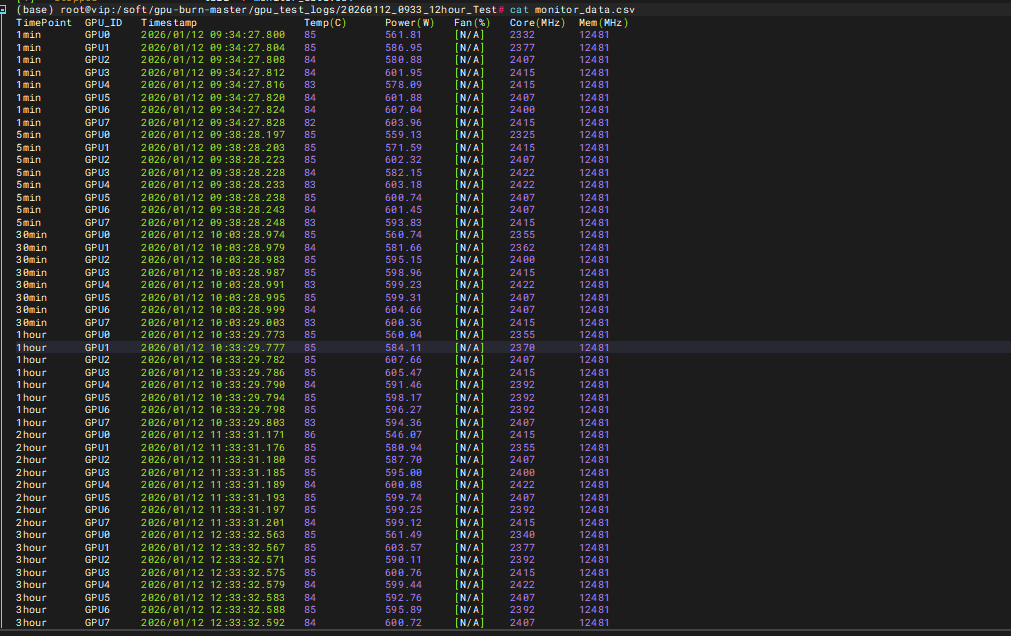
4小时-9小时测试结果
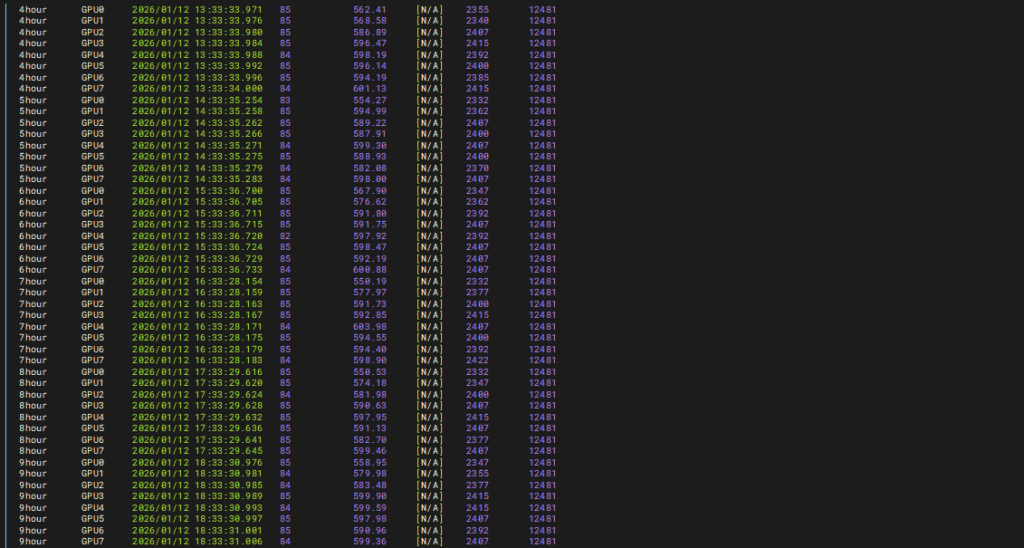
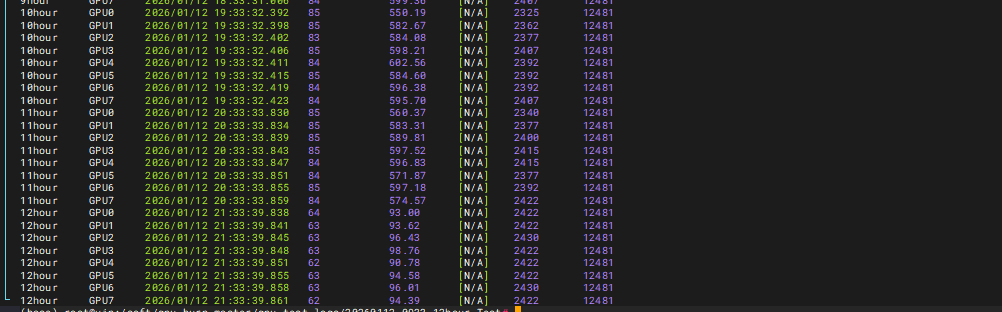
10-12小时测试结果
3).以下为平台在压力测试时电源总功耗:
4).以下为平台压力测试时传感器主要部件的温度等信息.
5).以下为(环温 30℃ , 风扇模式为自动模式)在对 Geforce 卡使用CV 算法压测 16h 的状态结果.
6).以下为(环温 30℃ , 风扇模式为自动模式)在对 Geforce 卡使用LLM 模型压测算法压测 16h 的状态结果.
5.1.2 系统重启测试
此项测试是重复并连续的对系统进行 2h 的重启操作,操作系统引导正常(无 Hang 机、报错等).
5.1.3 系统 AC 断电测试
此项测试主要模拟在异常断电或误操作情况下,系统仍然可以正常开机并引导至 OS.通过 30 次的系统断电测试,结果均符合测试要求.
5.2 系统及部件功能信息检查
5.2.1 CPU&MEM 关键部件的信息检查
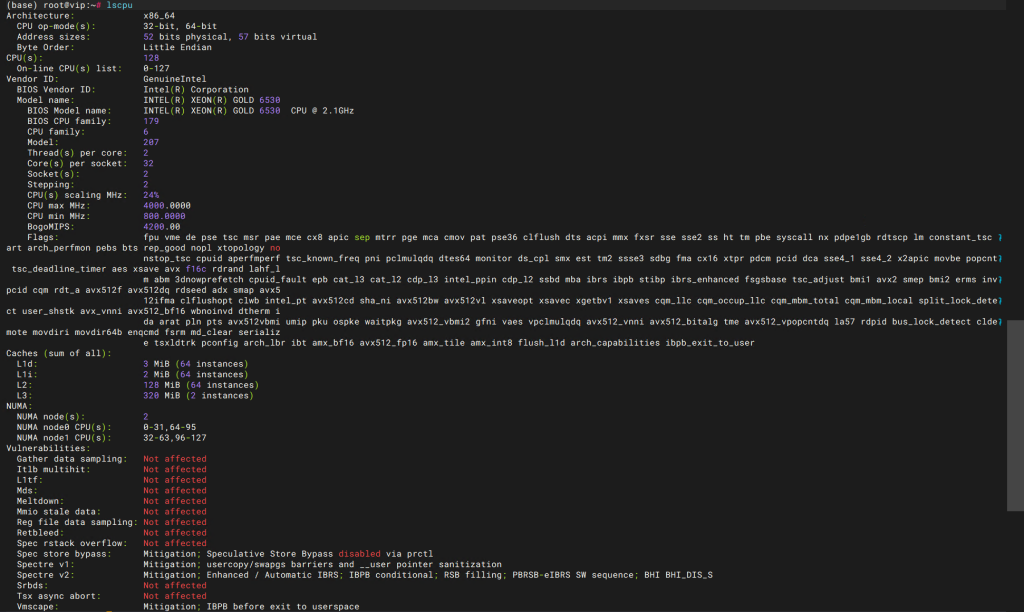
1).以下为 CPU&MEM 在 OS 下的信息.

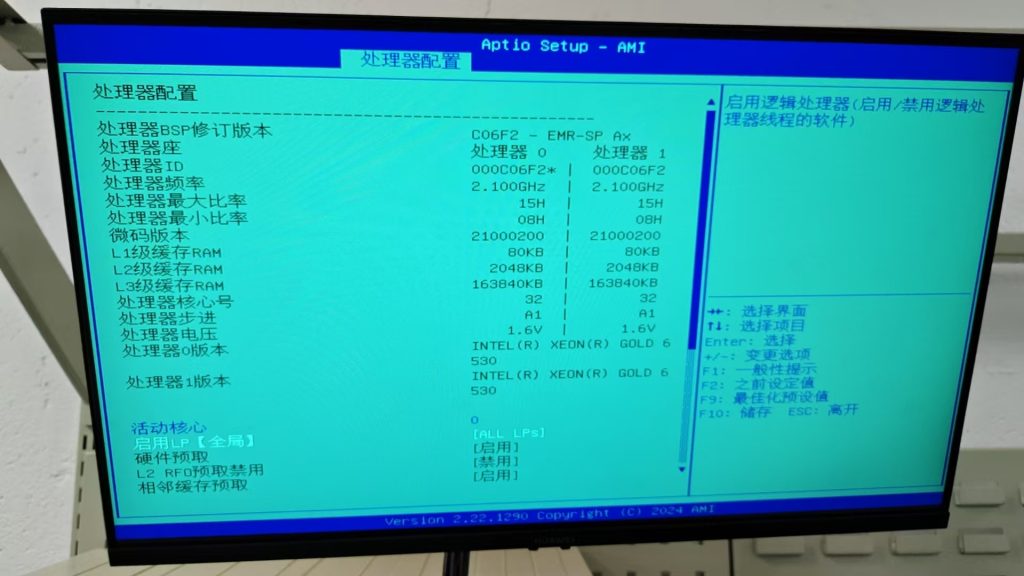
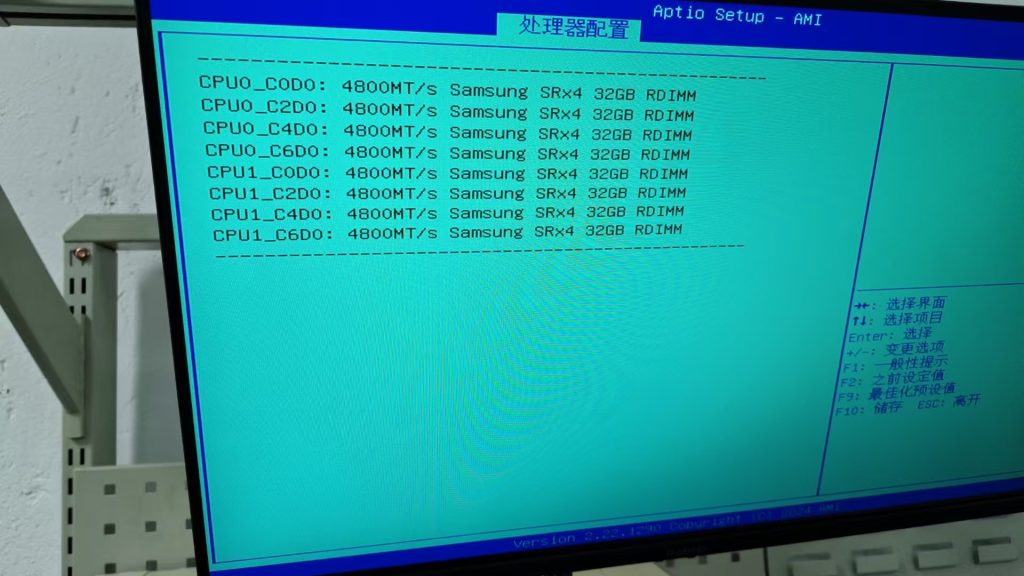
2).以下为 CPU&MEM 分别在 BIOS 下的信息
3).以下为 CPU&MEM 分别在 BMC 下的信息.
1 CPU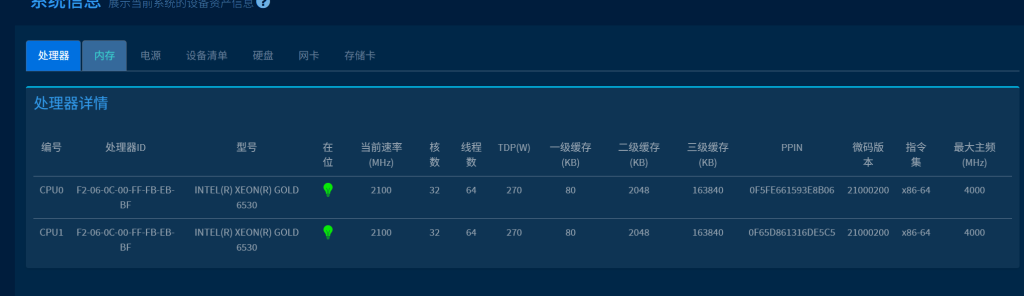
2 MEM
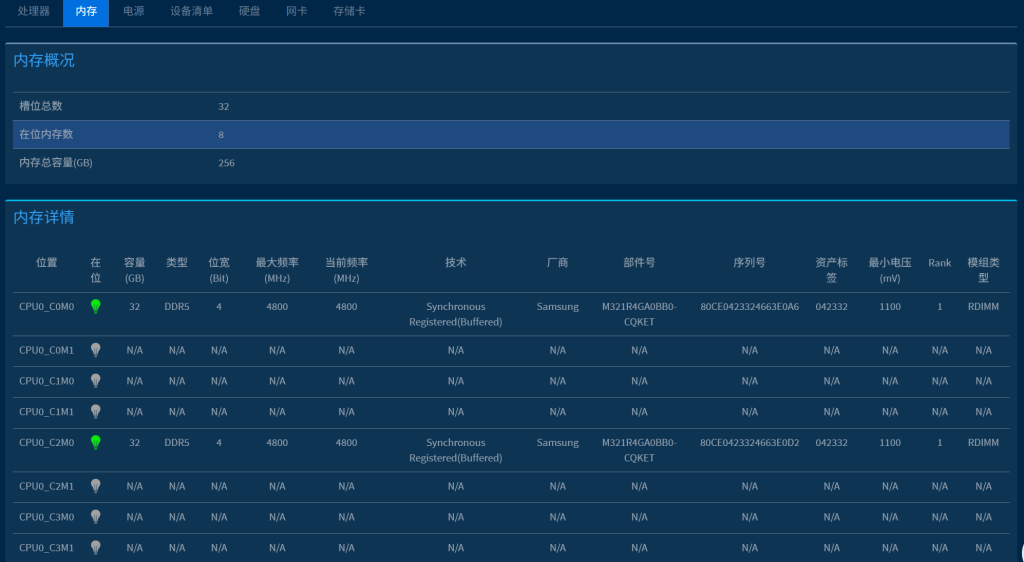
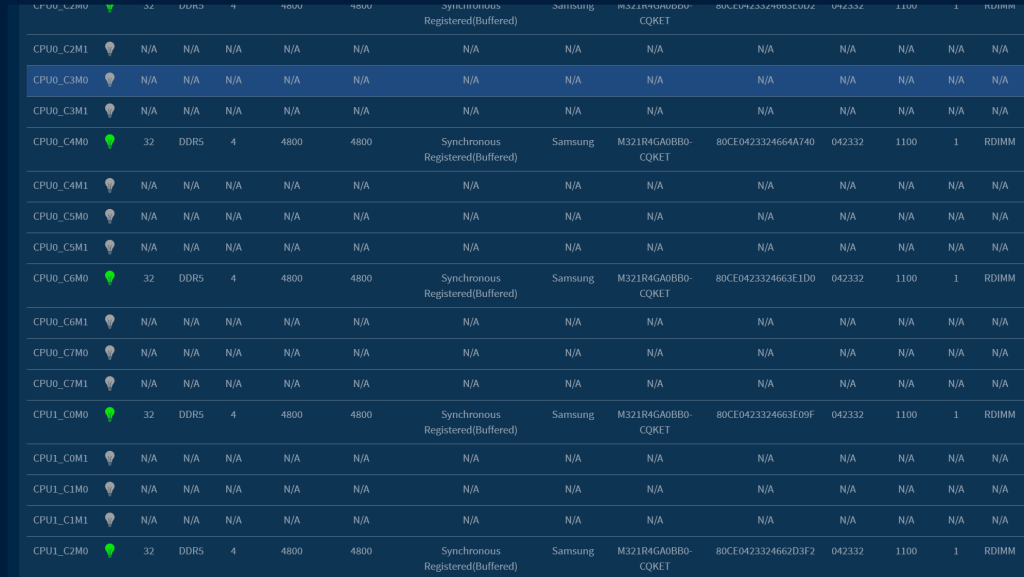
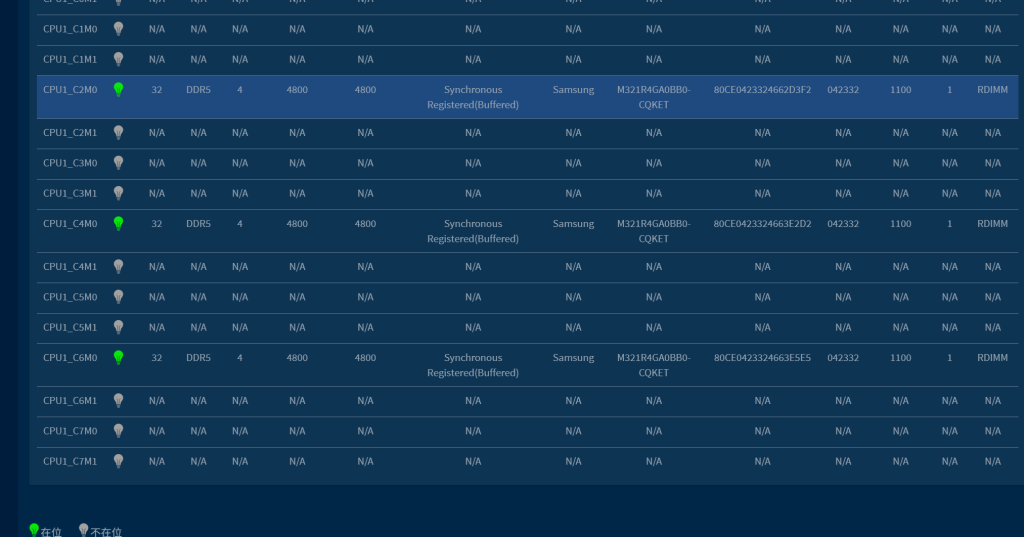
5.2.2 GPU 卡的信息检查
1).以下为 Geforce 单涡轮在 OS 下的硬件基本信息.
显卡实时结果
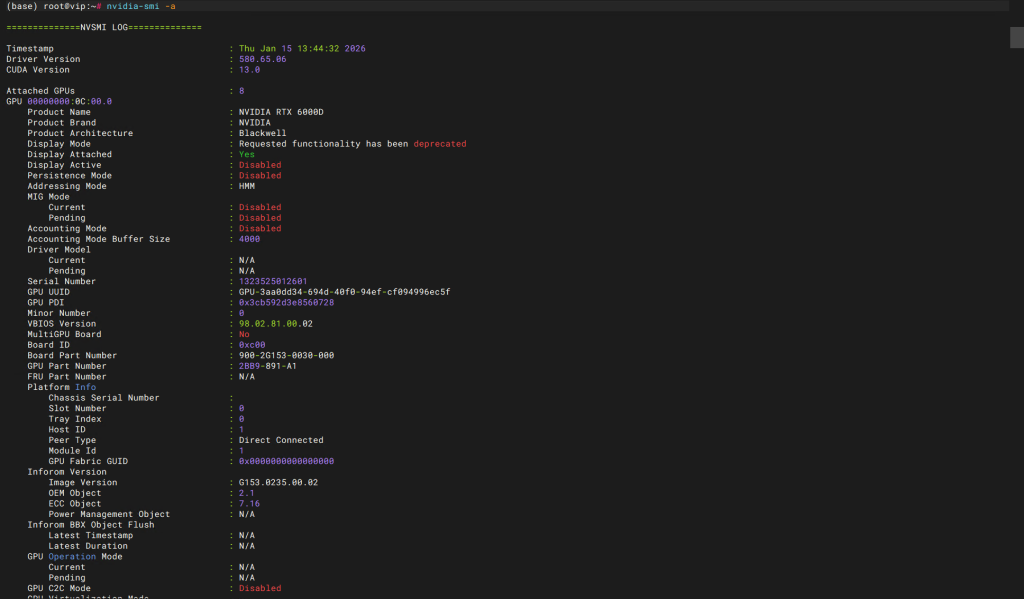
2).以下为 Geforce 单涡轮 GPU 卡在 BMC 下的信息.
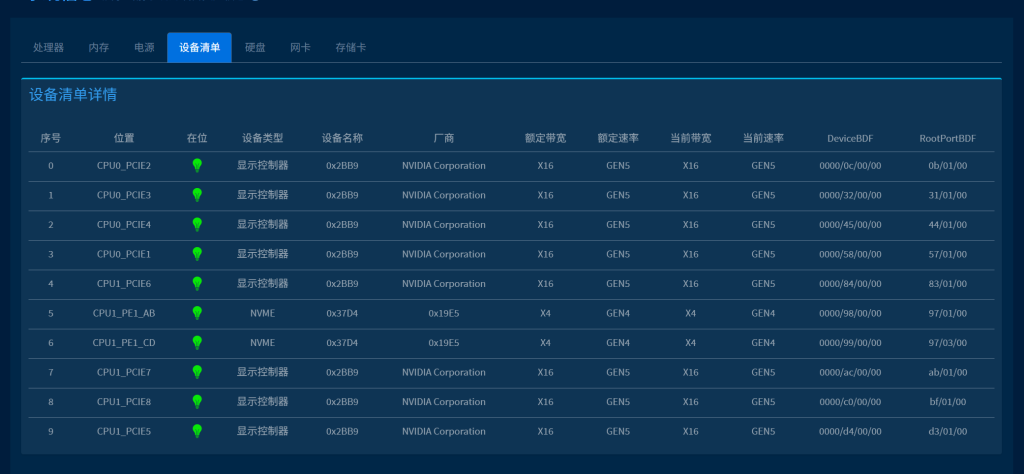
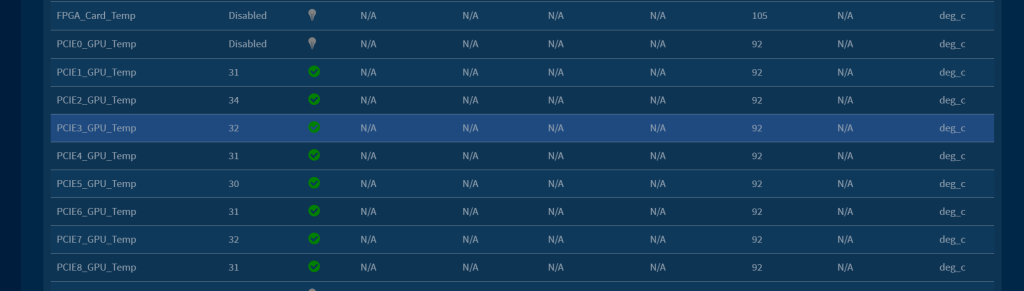
5.3 GPU 卡基础性能测试
5.3.1 PCIE 带宽测试
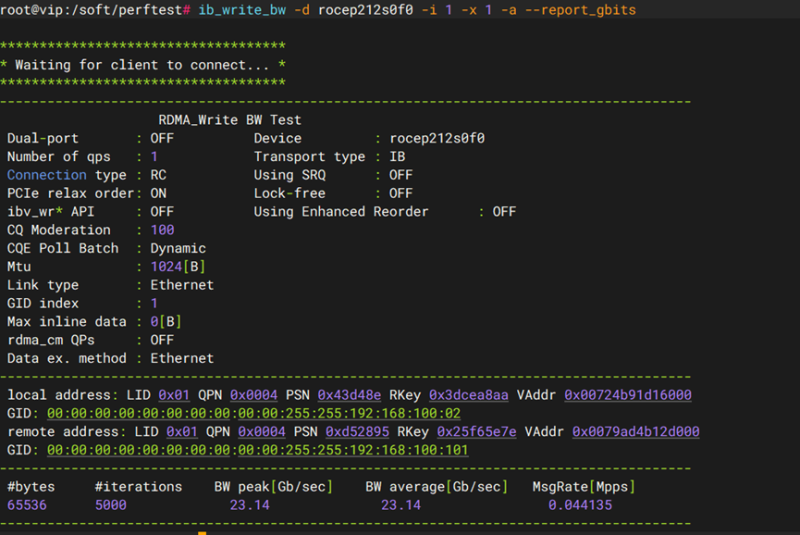
这里使用 cuda 自带的 bandwidthTest 测试工具对 进行PCIE 带宽测试,测试结果如下.
|
GPU Mode (Bus ID) |
Host to Device Bandwidth(GB/s) |
Device to Host Bandwidth(GB/s) |
Device to Device Bandwidth(GB/s) |
|
0 |
56.44 | 53.59 | 638.32 |
|
1 |
56.42 | 53.72 | 638.37 |
|
2 |
56.42 | 49.91 | 638.47 |
|
3 |
56.42 | 53.17 | 638.28 |
|
4 |
56.42 | 51.08 | 638.56 |
|
5 |
56.43 | 50.40 | 638.56 |
|
6 |
56.45 | 49.97 | 638.42 |
|
7 |
56.43 | 51.35 | 638.66 |
PCIE识别
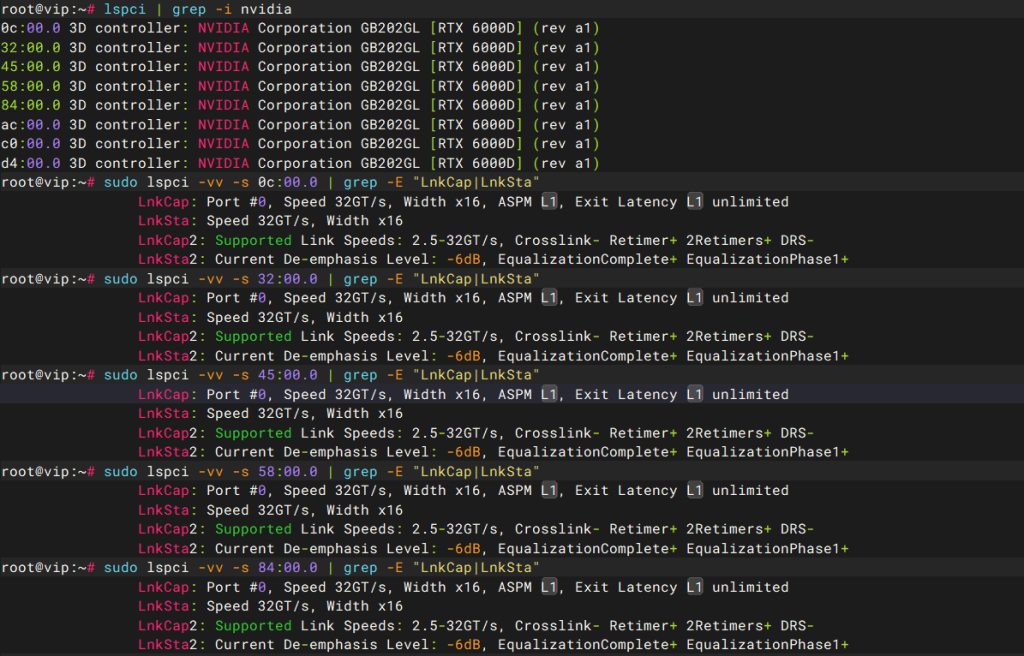
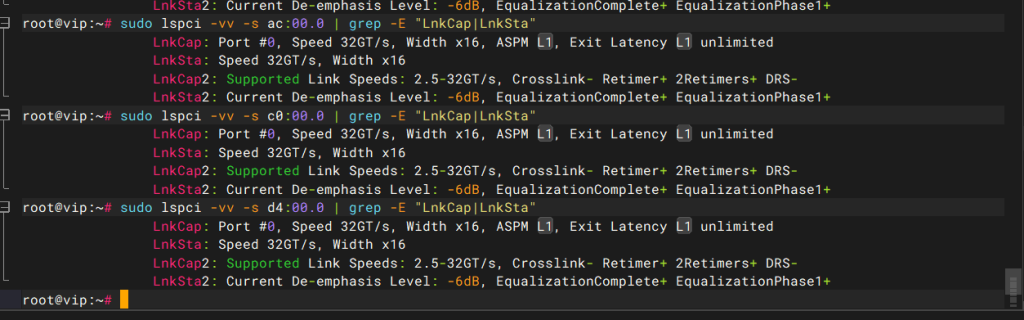
综上,pcie卡识别正常
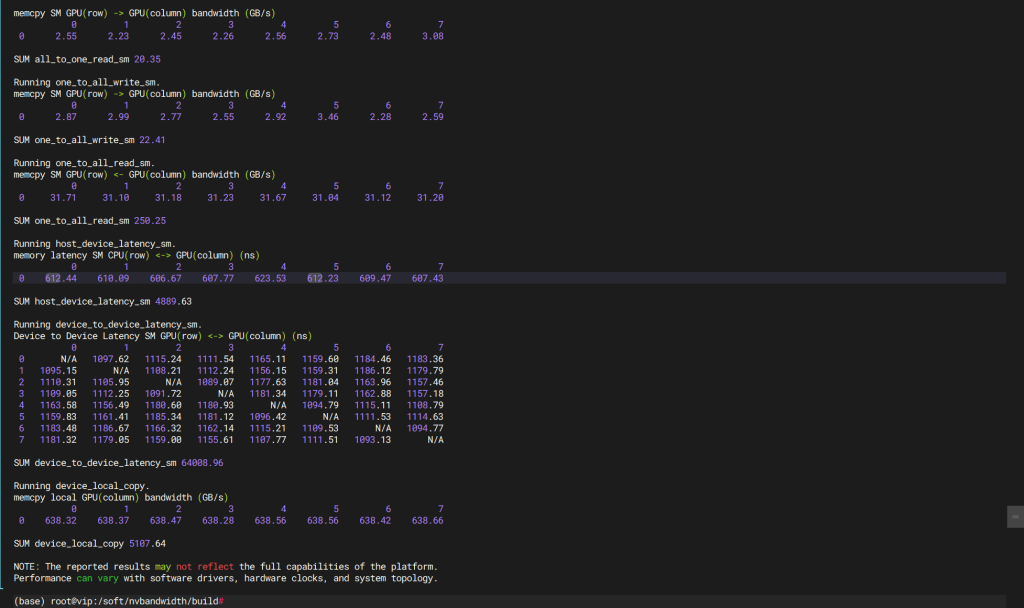
5.3.2 P2P 测试
这里使用 cuda 自带的 busGrind 测试,测试结果如下(XX根内存条件下进行测试).
5.3.3 NCCL 测试
使用NCCL 工具测试显卡分别在相同Node和不同Node 的测试结果(XX根内存条件下进行测试).
|
-b 8 -e 128M -f 2 -g 4 下相同 Node |
|
|
GPU Mode(Bus ID) |
Avg bus bandwidth |
|
4,5,6,7 |
|
|
0,1,2,3 |
|
|
-b 8 -e 128M -f 2 -g 4 下不同 Node |
|
|
GPU Mode(Bus ID) |
Avg bus bandwidth |
|
0,1,6,7 |
|
|
-b 8 -e 128M -f 2 -g 8 测试 |
|
|
GPU Mode(Bus ID) |
Avg bus bandwidth |
|
0,1,2,3,4,5,6,7 |
|
|
-b 1g -e 12g -f 2 -g 8 测试 |
|
|
GPU Mode(Bus ID) |
Avg bus bandwidth |
|
0,1,2,3,4,5,6,7 |
|
5.4 GPU 卡主流模型性能测试
5.4.1 主流模型 Resnet101 图像分类性能测试
在 XX平台上使用XX GPU 基于 Pytorch 框架运行深度学习ResNet101 模型,并基于 ImageNet(3x224x224)数据集相同样本数进行运算,测试 1 卡、2 卡、4 卡和8 卡条件下每秒运算图片数量.同时针对 1 卡、2 卡、 4 卡和8 卡的扩展测试计算其加速比.
|
项目 |
NVIDIA GPU 卡 |
|||
|
任务类型 |
图像分类 |
|||
|
数据集 |
ImageNet(3x224x224) |
|||
|
卡数量 |
1 卡 |
2 卡 |
4 卡 |
8 卡 |
|
显存(百分比) |
||||
|
每秒运算图片数量 |
||||
|
加速比 |
||||
5.4.2 NGC 容器下 Resnet50 AI 模型性能测试
在 TW G620X4平台上使用 Geforce 单涡轮 GPU 卡在 NGC 容器下基于Pytorch 框架运行深度学习 ResNet50 模型,并且基于 ImageNet 2012 数据集(ILSVRC2012_img_train、ILSVRC2012_img_val)相同样本数进行运算,测试每秒运算图片数量.
|
项目 |
GeforceGPU |
|||
|
任务类型 |
AI 性能测试 |
|||
|
数据集 |
ImageNet 2012 数据集 |
|||
|
卡数量 |
1 卡 |
2 卡 |
4 卡 |
8 卡 |
|
FP32 显存(百分比) |
||||
|
FP32 每秒运算图片数量 |
||||
|
加速比 |
||||
|
AMP 显存(百分比) |
||||
|
AMP 每秒运算图片数量 |
||||
|
加速比 |
||||
5.5 CPU 性能测试
5.5.1 CPU 整型数据处理性能
使用Intel Xeon Gold 6530CPUCPU 在 TW G620X4平台上运行 sysbench 基准测试工具,基于最大到 20000的素数进行 CPU 计算,测试在单线程以及多线程条件下每秒的计算速度,从而得到不同线程数参与计算时的性能.
|
CPU 线程数 |
每秒计算速度 |
平均计算延迟(ms) |
|
1 |
894.5 | 1.12 |
|
8 |
7128.53 | 1.12 |
|
16 |
14251.26 | 1.12 |
|
32 |
28518.28 | 1.12 |
|
48 |
40196.16 | 1.19 |
|
64 |
36209.89 | 1.77 |
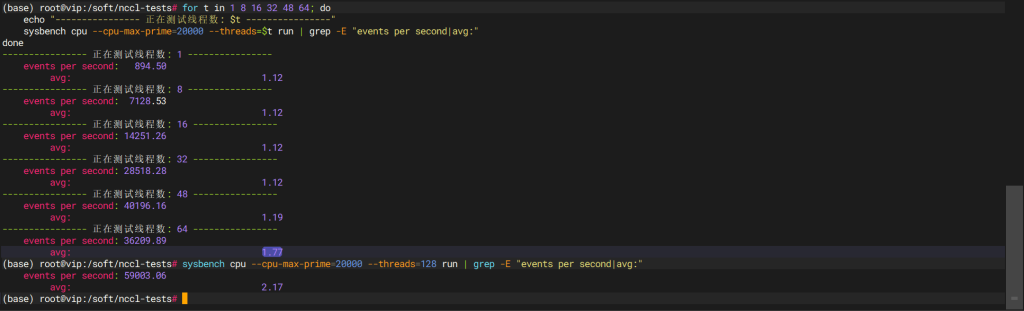
5.5.2 CPU 浮点数据处理性能
此项测试使用 SPECPU 测试工具利用 CPU 的浮点运算能力来计算出 π
(圆周率),以验证 Intel Xeon Gold 6530CPU 的计算能力。下图为计算 2 的 25 次方位&30 次方位π (圆周率)的结果:
5.6 MEM 性能测试
1).内存访问延迟矩阵.以下结果表示任意两个Numa node 之间(NPS4 设置)的空闲内存访问延迟,以ns为单位,观察以下延迟矩阵,数值大致关于对角线对称,并且访问延迟大致相同.由此可以判断节点间的内存访问是正常的.
2).内存访问带宽测试,非一致性内存访问(NUMA)启用时,本地内存延迟和跨插槽内存延迟会有显著差异。
3).以下结果显示了内存访问带宽和内存延迟之间的关系.在读操作条件下,随着机器负载的增加,内存访问带宽增加,内存响应也会相应变慢.
5.7 硬盘性能测试
此项性能测试使用FIO 工具,直连主板条件下进行的顺序读写、随机读写性能测试.以下为硬盘(华为ES3500P V6 3.84T U.2NVME SSD)直连主板异步性能数据
|
硬盘 |
盘数 |
顺序写入 (BW) |
顺序读取 (BW) |
随机写入(IOPS) |
随机读取(IOPS) |
| 华为ES3500P V6 3.84T U.2NVME SSD | 1 | 4877056 KB/s | 7397632 KB/s | 982390 IOPS | 1631018 IOPS |
5.8 噪声测试
系统满载条件下在机器正后方的噪声测试结果如下.
|
检测点与机器正后方距离 |
0.5m |
1m |
1.5m |
|
噪声 |
85db | 80db | 78db |
5.9 平台相关信息
|
TW G620X4 平台 |
|
|
支持的盘位&类型 |
|
|
接口 |
|
|
BUS_ID 与 SLOT对应关系 |
|
6、测试总结
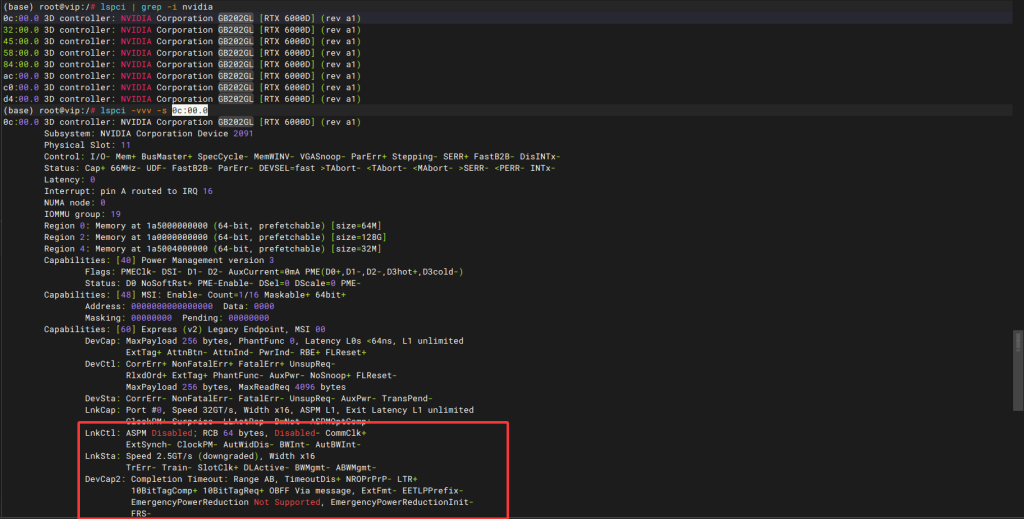
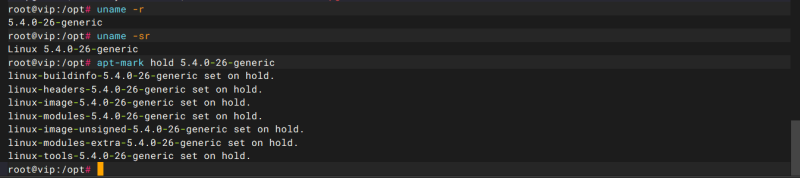
问题描述1,PCIE链路带宽
长期测试过程中发现PCIE链路变为PCIE1.0,怀疑与前面板多插了一张E830百G正相关

暂无评论内容